
Release notes for Groovy 6.0
Groovy 6 builds upon existing features of earlier versions of Groovy. In addition, it incorporates numerous new features and streamlines various legacy aspects of the Groovy codebase.
|
Highlights
Native Async/Await (incubating)
-
Sequential-style concurrent code — no callbacks or
CompletableFuturechains. -
Automatic virtual threads on JDK 21+; cached thread pool fallback on JDK 17–20.
-
Generators with
yield return, Go-style channels,for await, structured concurrency viaAsyncScope.
Integrated Concurrency Toolkit (incubating)
-
Unified
groovy.concurrentpackage: agents, actors, dataflow variables, channels, and parallel collections. -
@ActiveObjectadds actor semantics to ordinary classes — no message protocols to hand-write. -
Parallel
Collectionmethods (collectParallel,findAllParallel,eachParallel, …) for CPU-bound work. -
Same APIs available to Java, Kotlin and other JVM languages via the standalone
groovy-concurrent-javamodule.
New Language Features
-
valcontextual keyword for final declarations — a clean companion tovar. -
Module imports (JEP 511):
import module java.sqlcovers every exported package in one line even on JDK17. -
Additional destructuring e.g. with rest binders:
def (h, *t) = list. -
Compound-assignment operator overloading (
plusAssign,minusAssign, …) for efficient in-place mutation, even onfinalfields. -
Intersection-type cast for lambdas, method references and closures —
(Runnable & Serializable) () → …. -
AST transforms now valid on loop statements —
@Parallelfor-loops,@Invariant,@Decreases. -
Nested
copyWithfor@Immutable/@RecordType— dotted-path map keys and a transactional block form, with structural sharing preserved.
-
New
NullCheckertype checker with an optional flow-sensitivestrictmode requiring no annotations. -
@Modifiesframe conditions and@Purepurity declarations, verified at compile time byModifiesCheckerandPurityChecker. -
CombinerCheckerverifies parallel-reduction combiners are associative, via new@Associative/@Reducerdeclarations. -
DOmacro forfor/do-style monadic comprehensions across the standard JVM carriers, FunctionalJava and Vavr control types, and user@Monadictypes — withMonadicCheckerandMonadicShapeCheckerenforcing the carrier shape at compile time. -
Loop invariants and termination measures via
@Invariant/@Decreases. -
Contracts (
@Requires,@Ensures,@Invariant) now also work in scripts. -
Each method becomes a self-contained specification — readable without descending into bodies.
-
Those verified declarations are machine-actionable — a foundation for AI skills and tooling, not just for reading.
-
groovy-concurrent-java— Standalone Java library exposing thegroovy.concurrenttoolkit; no Groovy runtime required. -
groovy-http-builder— HTTP client with imperative DSL and declarative@HttpBuilderClientinterface. Auto-parsed JSON, XML and HTML responses; typed return objects driven by interface signatures. -
groovy-csv— RFC 4180 CSV reading/writing with optional Jackson-backed typed parsing. -
groovy-markdown— CommonMark parser with section, code-block and table extraction helpers. -
groovy-grape-ivy—@GrabIvy backend, now its own optional module (previously bundled in core). -
groovy-grape-maven—@Grabpowered by Maven Resolver, alongside the existing Ivy engine. -
groovy-reactor/groovy-rxjava—awaitandfor awaitover reactiveMono/Flux/Observabletypes. -
groovy-test-junit6— Run JUnit Jupiter 6 tests as Groovy scripts.
Existing Module Improvements
-
GINQ provides a cleaner
groupby … intowhich binds a group to a named variable with aggregate access, and gains SQL-style set operators:union,intersect,minus,unionall. -
Consistent typed parsing across JSON, CSV, TOML, YAML and XML modules.
-
New methods including
groupByMany,waitForResult,findGroups/findAllGroups,isSorted,zipWithNext/groupConsecutive, and lazygrepping. -
Asynchronous file I/O on
Path(textAsync,bytesAsync,writeAsync) returningCompletableFuture— composes withawait. -
Streamlined process handling:
pipeline,onExit,toProcessBuilder, named-parameterexecute(dir:, env:, …).
Tooling Improvements
-
GroovyDoc adds JEP 467 Markdown doc comments (
///) and JEP 413{@snippet}blocks for inline and external code samples. Also added is Prism.js syntax highlighting, class-hierarchy tree pages,{@value}/{@inheritDoc}support, and improved script documentation. -
Light, dark, "follow system" and custom themes for GroovyDoc, the GDK reference, and GroovyConsole.
-
Groovysh gains an
/imgcommand for inline images and charts using JLine’s terminal-graphics support, Markdown handling in/slurp.
JDK/Java Integration Improvements
-
Tested across JDK 17–26; JDK 17 is now the minimum supported runtime. Module import already mentioned.
-
Joint Compilation Stub Improvements: AST-transform-generated members (
@Immutable,@Builder,@TupleConstructor,@Delegate, …) are now visible in generated stubs. Java code in mixed-language projects can finally call constructors and methods contributed by transforms.
New Modules
Groovy 6 ships eight new optional modules, plus a long-standing piece of core (Grape’s Ivy backend) is split out into its own module:
| Module | Purpose |
|---|---|
|
Standalone Java library exposing the |
|
CSV parsing and writing via Jackson CSV |
|
|
|
New |
|
Imperative DSL and declarative annotation-driven client over JDK
|
|
CommonMark Markdown parser |
|
AwaitableAdapter SPI for
Project Reactor ( |
|
|
|
Groovy runner for JUnit 6 (Jupiter) tests as scripts |
Each module has a dedicated section below covering its public API, examples, and any migration notes.
Native Async/Await (incubating)
Groovy 6 adds native async/await support
(GROOVY-9381),
enabling developers to write concurrent code in a sequential, readable style — no callbacks, no java.util.concurrent.CompletableFuture chains, no manual thread management.
On JDK 21+, tasks automatically leverage virtual threads.
See also the async/await blog post for a detailed walkthrough.
Before and after
Without async/await, concurrent code requires chaining futures:
// Before: CompletableFuture chains
def future = CompletableFuture.supplyAsync { loadUserProfile(id) }
.thenCompose { profile -> CompletableFuture.supplyAsync { loadQuests(profile) } }
.thenApply { quests -> quests.find { it.active } }
def quest = future.join()With async/await, the same logic reads like synchronous code:
// After: sequential style, concurrent execution
def quest = await async {
def profile = await async { loadUserProfile(id) }
def quests = await async { loadQuests(profile) }
quests.find { it.active }
}Exception handling works with standard try/catch — no .exceptionally() chains.
Parallel tasks and combinators
Launch tasks concurrently and coordinate results:
def a = async { fetchFromServiceA() }
def b = async { fetchFromServiceB() }
def c = async { fetchFromServiceC() }
// Wait for all three
def (resultA, resultB, resultC) = await(a, b, c)Generators with yield return
An async closure containing yield return becomes a lazy generator — it produces values on demand with natural back-pressure:
def fibonacci = async {
long a = 0, b = 1
while (true) {
yield return a
(a, b) = [b, a + b]
}
}
assert fibonacci.take(8).collect() == [0, 1, 1, 2, 3, 5, 8, 13]Channels
Go-style inter-task communication. A producer sends values into a channel (AsyncChannel); a consumer receives them:
def ch = AsyncChannel.create(5) // buffered channel
async {
for (i in 1..10) ch.send(i)
ch.close()
}
for (val in ch) { println val } // prints 1..10Structured concurrency
AsyncScope binds the lifetime of child tasks to a scope — when the scope exits, all children are guaranteed complete or cancelled:
AsyncScope.run {
def users = async { loadUsers() }
def config = async { loadConfig() }
processResults(await(users), await(config))
}
// Both tasks guaranteed complete hereFeature summary
| Feature | Description |
|---|---|
|
Start background tasks; collect results in sequential style |
Virtual threads |
Automatic on JDK 21+; cached thread pool fallback on JDK 17—20 |
Awaitable |
Wait for all tasks to complete |
|
Race — first to complete wins |
|
First success wins (ignores individual failures) |
|
Wait for all; inspect each outcome individually |
|
Lazy generators with back-pressure |
Buffered and unbuffered Go-style channels |
|
|
Iterate over async sources (generators, channels, reactive streams) |
|
LIFO cleanup actions, runs on scope exit regardless of success/failure |
|
Structured concurrency — child lifetime bounded by scope |
Timeouts |
|
|
Non-blocking pause |
|
|
Framework adapters (SPI) |
|
Executor configuration |
Pluggable; default auto-selects virtual threads or cached pool |
See the Async/Await user guide for the full API and additional examples.
Integrated Concurrency and Parallel Processing (incubating)
Groovy 6 brings a unified concurrency and parallel-processing toolkit
into core under
GEP-18: Integrated Concurrency and Parallel Processing
(GROOVY-11952,
GROOVY-11953).
The new abstractions live in the groovy.concurrent package and
modernise patterns from
GPars around virtual threads, structured concurrency,
and Groovy 6’s async/await. The same combinators
(await, Awaitable.all, for await) work uniformly across all of
them — agents, actors, dataflow variables, channels, and parallel
collections — so you compose features rather than learning separate
APIs.
For Java-only consumers, the same APIs are also published as the
new groovy-concurrent-java module — see Java-only module: groovy-concurrent-java.
Agents — thread-safe mutable state
An Agent wraps a value and serialises
updates via functions, eliminating data races by design. Reads compose
with await:
import groovy.concurrent.Agent
def counter = Agent.create(0)
counter.send { it + 1 }
counter.send { it + 1 }
counter.send { it + 1 }
assert await(counter.getAsync()) == 3An agent also exposes its update stream as a
java.util.concurrent.Flow.Publisher via changes(), so for await
consumes state transitions directly:
def agent = Agent.create(0)
async {
3.times { agent.send { it + 1 } }
agent.shutdown()
}
def seen = []
for await (v in agent.changes()) { seen << v }
assert seen == [1, 2, 3]@ActiveObject — actor semantics with class syntax
A hand-written actor (Actor) expresses concurrency by encoding a message
protocol — typed messages, a switch over message kinds, and explicit
send/sendAndGet plumbing at every call site:
import groovy.concurrent.Actor
// Hand-written actor — message protocol explicit
def account = Actor.stateful(0.0) { balance, msg ->
switch (msg) {
case { it instanceof Map && it.deposit }:
return balance + msg.deposit
case { it instanceof Map && it.withdraw }:
if (msg.withdraw > balance) throw new RuntimeException('Insufficient funds')
return balance - msg.withdraw
default: return balance
}
}
account.send([deposit: 100])
account.send([withdraw: 30])
def balance = await(account.sendAndGet([deposit: 0]))
assert balance == 70.0To know whether the actor is being used safely, a reader (human or AI)
has to follow each message kind through the dispatch loop and match it
against every call site. @ActiveObject
(applicable target: TYPE) inverts this: write a normal class, mark methods that participate in
the actor’s serialised mailbox with
@ActiveMethod (applicable target: METHOD), and the AST
transform routes those calls through an internal actor:
import groovy.transform.ActiveObject
import groovy.transform.ActiveMethod
@ActiveObject
class Account {
private double balance = 0
@ActiveMethod
void deposit(double amount) { balance += amount }
@ActiveMethod
void withdraw(double amount) {
if (amount > balance) throw new RuntimeException('Insufficient funds')
balance -= amount
}
@ActiveMethod
double getBalance() { balance }
}
def account = new Account()
account.deposit(100)
account.deposit(50)
account.withdraw(30)
assert account.getBalance() == 120.0The thread-safety contract is now explicit and local. The
@ActiveObject annotation declares the concurrency model;
@ActiveMethod bodies contain plain business logic; callers see
ordinary method calls — no message types to invent, no switch to
parse, no manual reply plumbing. For non-blocking use,
@ActiveMethod(blocking = false) returns an Awaitable that plugs
straight into await and Awaitable.all.
Dataflow variables
A DataflowVariable is a
single-assignment variable: any thread that reads before it is bound
blocks until a value is available. DataflowVariable implements
Awaitable, so it composes directly with await and async {}
regardless of which task binds first:
import groovy.concurrent.DataflowVariable
def x = new DataflowVariable()
def y = new DataflowVariable()
def z = new DataflowVariable()
async { z << await(x) + await(y) } // blocks until x and y bind
async { x << 10 } // bind in any order
async { y << 5 }
assert await(z) == 15The companion Dataflows class
auto-creates variables on property access for an even more concise
form (async { df.fullName = "${df.first} ${df.last}" }).
Parallel collections
For CPU-bound data parallelism, Collection gains a family of
parallel methods backed by a ForkJoinPool:
def squares = (1..1_000).toList().collectParallel { it * it }
def adults = people.findAllParallel { it.age >= 18 }
def total = amounts.sumParallel { a, b -> a + b }ParallelScope.withPool
binds a pool for a block, and Pool
offers Pool.cpu(), Pool.fixed(n), Pool.io(), and
Pool.virtual() factories so CPU-bound and I/O-bound workloads can
use distinct pools without leaking into the common pool. The
previously introduced @Parallel loop
annotation shares this infrastructure:
import groovy.concurrent.ParallelScope
import groovy.concurrent.Pool
ParallelScope.withPool(Pool.cpu()) { scope ->
def hot = bigList.findAllParallel { it.score > threshold }
hot.eachParallel { archive(it) }
}As a rule of thumb, prefer parallel collections (or @Parallel) for
CPU-bound work and async/await with virtual threads for
I/O-bound work — ForkJoinPool workers are precious and should not
be tied up in Thread.sleep, network calls, or blocking I/O.
Channel composition and broadcast
AsyncChannel (introduced with async/await) gains composable
pipeline operations — filter, map, merge, split, tap — and
ChannelSelect for Go-style
multi-channel selection.
BroadcastChannel adds
one-to-many delivery and exposes asPublisher() for direct
Flow.Publisher interop, so any subscriber — including a for await
loop — receives every message:
import groovy.concurrent.BroadcastChannel
def broadcast = BroadcastChannel.create()
def publisher = broadcast.asPublisher()
async {
['hello', 'world'].each { broadcast.send(it) }
broadcast.close()
}
for await (msg in publisher) { println msg } // hello, worldThe same for await works against any JDK Flow.Publisher, Reactor
Flux (via groovy-reactor), or RxJava Observable (via
groovy-rxjava).
Java-only module: groovy-concurrent-java
For Java, Kotlin, and other JVM languages that want the same
toolkit without the full Groovy runtime, the standalone
groovy-concurrent-java module exposes AsyncScope, Pool,
ParallelScope, Actor, Agent, DataflowVariable,
AsyncChannel, BroadcastChannel, and ChannelSelect against
plain java.util.function types. The Groovy-only sugar
(async/await keywords, for await, defer, @ActiveObject,
Dataflows, parallel extension methods) requires the full Groovy
dependency.
import groovy.concurrent.AsyncScope;
import org.apache.groovy.runtime.async.AsyncSupport;
var result = AsyncScope.withScope(scope -> {
var a = scope.async(() -> fetchUser(id));
var b = scope.async(() -> fetchOrders(id));
return Map.of(
"user", AsyncSupport.await(a),
"orders", AsyncSupport.await(b)
);
});The module ships under the org.apache.groovy:groovy-concurrent-java
coordinate and is mutually exclusive with the full groovy runtime
(Gradle enforces this via a shared capability; a runtime warning
fires if both jars are detected on the classpath).
Feature summary
| Feature | Description | Ticket |
|---|---|---|
|
Thread-safe mutable value updated via serialised functions; exposes
a |
|
|
Stateless and stateful actors with |
|
|
AST-driven actor semantics with class syntax. |
|
|
Single-assignment variables; |
|
|
Composable channel pipelines. |
|
|
One-to-many broadcast (with |
|
Parallel collection methods |
|
|
|
|
|
|
Standalone Java module exposing the same concurrent APIs without the Groovy runtime. |
See the user guides for the full APIs and additional examples: concurrent actors and agents, concurrent dataflow, parallel collections, and the Java-only module.
HttpBuilder: HTTP Client Module (incubating)
Groovy 6 introduces a new groovy-http-builder module
(GROOVY-11879,
GROOVY-11924)
providing both an imperative DSL and a declarative annotation-driven
client over the JDK’s java.net.http.HttpClient.
It is designed for scripting, automation, and typed API clients,
filling the gap left by the earlier HttpBuilder/HttpBuilder-NG libraries.
The two entry points are HttpBuilder
for the imperative DSL and
@HttpBuilderClient for the
declarative client; supporting types live in the groovy.http package.
Applicable targets for the new annotations: @HttpBuilderClient — TYPE;
@Get/@Post/@Put/@Delete/@Patch/@Form/@Timeout — METHOD;
@Body/@BodyText/@Query — PARAMETER;
@Header — TYPE, METHOD.
Imperative DSL
A closure-based DSL for quick scripting:
import static groovy.http.HttpBuilder.http
def client = http('https://api.github.com')
def result = client.get('/repos/apache/groovy')
assert result.json.license.name == 'Apache License 2.0'Responses auto-parse by content type: result.json, result.xml,
result.html (via jsoup), or result.parsed for auto-dispatch.
Declarative client
Define a typed interface and Groovy generates the implementation at compile time. Parameters are mapped by convention — no annotations needed for the common case:
@HttpBuilderClient('https://api.example.com')
interface UserApi {
@Get('/users/{id}')
User getUser(String id) // path param: {id}
@Get('/users')
List<User> search(String name) // implied query param: ?name=...
@Post('/users')
User create(@Body Map user) // JSON body
@Post('/login')
@Form
Map login(String username, String password) // form-encoded
}
def api = UserApi.create()
def user = api.getUser('42')Async support
Both sides offer native async via HttpClient.sendAsync() — no
extra threads consumed while waiting:
// Imperative
def future = client.getAsync('/slow-endpoint')
def result = future.get()
// Declarative
@HttpBuilderClient('https://api.example.com')
interface AsyncApi {
@Get('/data/{id}')
CompletableFuture<Map> getData(String id)
}These CompletableFuture returns are first-class await targets in
Groovy 6: def data = await api.getDataAsync('42').
Feature summary
| Feature | Imperative | Declarative |
|---|---|---|
HTTP methods (GET, POST, PUT, DELETE, PATCH) |
All |
|
JSON body / response |
|
@Body / return-type driven |
Form-encoded body |
|
|
Plain text body |
|
|
XML / HTML response |
|
|
Typed response objects |
Manual ( |
Automatic (return type driven) |
Query parameters |
|
Implied from parameter name (or @Query) |
Path parameters |
Manual |
Auto-mapped via |
Headers |
|
@Header on interface/method |
Async |
|
|
Timeouts (connect / request) |
Config DSL |
|
Per-method timeout |
Per-request |
@Timeout |
Redirect following |
Config DSL |
|
Error handling |
Manual (check |
Auto-throw; custom exception via |
JDK client access (auth, SSL, proxy) |
|
|
See the HTTP client user guide for the full API and configuration options.
AST Transforms in More Places (incubating)
Groovy 6 extends the AST transformation infrastructure to support
annotations on loop statements — for-in, classic for, while, and do-while
(GROOVY-11878).
The following built-in transforms now declare LOOP as a valid target:
-
@Parallel — runs each iteration on its own task; uses virtual threads on JDK 21+ and falls back to platform threads otherwise (applicable target:
LOOPonly) -
@Invariant — asserts a condition at the start of each iteration (also valid on imports; see Groovy-Contracts Enhancements)
-
@Decreases — loop termination measure; see Groovy-Contracts Enhancements
-
@ASTTest — compile-time AST inspection utility used primarily for transform development and testing
@Parallel is the most visible application:
@Parallel
for (int i in 1..4) {
println i ** 2
}
// Output (non-deterministic order): 1, 16, 9, 4Custom transforms can opt into loop targeting by declaring
@ExtendedTarget(ExtendedElementType.LOOP), following the same
contract as class/method/field-level transforms. See
Improved Annotation Validation for the corresponding compile-time
validation rules.
Groovy-Contracts Enhancements
The groovy-contracts module receives several enhancements in Groovy 6,
including support for contracts in scripts, loop annotations,
and frame conditions. The module itself graduates from incubating to
stable in 6.0 (see Stabilised features); the newest of these enhancements — loop-level annotations and @Modifies frame conditions, which build on
the still-incubating loop AST-transform support — remain incubating for
this release.
Contracts in scripts
Contract annotations now work in Groovy scripts, not just inside classes (GROOVY-11885). @Requires and @Ensures can be placed on script methods, and @Invariant can be placed on an import statement to apply as a class-level invariant for the script:
@Invariant({ balance >= 0 })
import groovy.transform.Field
import groovy.contracts.Invariant
@Field Integer balance = 5
@Requires({ balance >= amount })
def withdraw(int amount) { balance -= amount }
def deposit(int amount) { balance += amount }
deposit(5) // balance = 10, OK
withdraw(20) // throws ClassInvariantViolation (balance would be -5)Combining contracts
These annotations can be combined to build strong confidence in the correctness of an algorithm. Consider this insertion sort that merges two pre-sorted lists:
@Ensures({ result.isSorted() })
List insertionSort(List in1, List in2) {
var out = []
var count = in1.size() + in2.size()
@Invariant({ in1.size() + in2.size() + out.size() == count })
@Decreases({ [in1.size(), in2.size()] })
while (in1 || in2) {
if (!in1) return out + in2
if (!in2) return out + in1
out += (in1[0] < in2[0]) ? in1.pop() : in2.pop()
}
out
}The @Ensures postcondition verifies that the result is sorted.
The @Invariant asserts that no elements are lost or gained — the total number of elements across all three lists stays constant
throughout the loop. The @Decreases annotation uses a lexicographic
measure over the two input list sizes, giving us confidence that
the loop terminates: on each iteration at least one input list
shrinks, and they can never grow.
See also the loop invariants blog post for more on how contracts support correctness reasoning.
Feature summary
| Feature | Description | Ticket |
|---|---|---|
|
Assert a condition at the start of each iteration of any loop type
(for-in, classic for, while, do-while). Multiple invariants can be stacked.
Violations throw |
|
Loop termination measure (loop variant). Takes a closure returning a
value or list of values that must strictly decrease each iteration while
remaining non-negative. Lists use lexicographic comparison.
Violations throw |
||
Frame condition declaring which fields a method may change.
Everything not listed is guaranteed unchanged.
@Pure is shorthand for |
||
Contracts in scripts |
|
|
|
Postconditions are now supported on |
Monadic Comprehensions (incubating)
Groovy 6 introduces DO — a comprehension macro that gives Scala
for-comprehension and Haskell do-notation ergonomics to any type
with monadic shape. See GEP-23: Monadic
comprehensions
(GROOVY-12021) for
the full specification.
A DO block rewrites at compile time to a chain of bind operations on
a participating carrier type. The notation reads top-to-bottom;
short-circuiting (empty Optional, failed Try, failed Awaitable)
is delivered by the carrier rather than by the macro.
import static org.apache.groovy.macrolib.MacroLibGroovyMethods.DO
@TypeChecked(extensions = 'groovy.typecheckers.MonadicChecker')
Optional<String> greet(Map<String, String> users, String userId) {
DO(user in Optional.ofNullable(users[userId]),
name in Optional.ofNullable(user.split(/\|/)[0])) {
Optional.of("Hello, $name!".toString())
}
}
assert greet([u42: 'Alice|admin'], 'u42').get() == 'Hello, Alice!'
assert greet([u42: 'Alice|admin'], 'u99') == Optional.empty()The same shape works over Stream, CompletableFuture,
Awaitable and
DataflowVariable, and over
FunctionalJava and Vavr control carriers (recognised by name, no
Groovy dependency on the library).
Carrier participation
A type participates as a carrier via one of four routes:
-
Standard allow-list (by type). Stdlib and Groovy-core carriers recognised by
Class:Optional,Stream,CompletionStage(coveringCompletableFuture), andAwaitable(coveringDataflowVariable). -
Standard allow-list (by name). Common third-party carriers recognised by fully-qualified name, with no Groovy dependency on the library:
Carrier bind map fj.data.Optionbindmapfj.data.Listbindmapfj.data.Streambindmapfj.data.Validationbindmapfj.P1bindmapio.vavr.control.OptionflatMapmapio.vavr.control.TryflatMapmapio.vavr.control.EitherflatMapmapio.vavr.control.ValidationflatMapmap -
Structural match. A type that exposes a single-argument
flatMap(and, for the map role,map) qualifies without further declaration. -
@Monadic opt-in. A user type that declares the annotation participates even when its method names diverge from the structural convention. The annotation may name alternative
bind/mapmethods, and optionally aunit(theof/purefactory that lifts a value into the carrier) — unused byDOitself but available to law-deriving and law-checking tooling. A data-style carrier should also provide structuralequals/hashCode, since a comprehension composes monadic values up to value equality.
MonadicChecker and MonadicShapeChecker
Under @CompileStatic/@TypeChecked,
MonadicChecker enforces
carrier participation, asserts the closure-return shape of DO chains
(catching bare-value and cross-carrier bodies), and restores the
comprehension’s static result type through the rewritten chain. It is
activated the same way as every other type-checking extension —
@TypeChecked(extensions = 'groovy.typecheckers.MonadicChecker'),
already shown in the example above.
MonadicShapeChecker is a
sibling extension that lints hand-written
flatMap/map/thenCompose/thenApply chains over the same carrier
set, independent of DO. It catches three high-confidence problems:
flatMap returning a non-carrier, flatMap returning a different
carrier, and map returning the same carrier (the M<M<T>>
foot-gun). The first two would be compile errors in Java, but Groovy’s
single-abstract-method coercion of closures normally lets them
through; the checker restores the Java guarantee. The third compiles
cleanly in both Java and Groovy — an Optional<Optional<Integer>> is
a well-typed value, just (almost certainly) not the one the author
intended.
The two extensions are complementary but independent: MonadicChecker
covers DO-macro rewrites, MonadicShapeChecker covers native chains.
Code that mixes both forms may opt into both.
Feature summary
| Feature | Description | Ticket |
|---|---|---|
|
Compile-time rewrite of generator/body comprehensions into a chain
of bind operations on a participating carrier. Recognises stdlib and
Groovy-core carriers by type; FunctionalJava and Vavr control carriers
by fully-qualified name; structural and |
|
Opt-in marker for user types whose bind/map methods diverge from the
structural convention. Optional |
||
Type-checking extension that enforces carrier participation, the
closure-return shape of |
||
Sibling extension that lints hand-written
|
||
Carrier registry |
Standard allow-list shared by the runtime bind/map dispatcher and the type-checking extensions; covers stdlib carriers by type and FunctionalJava / Vavr carriers by name. |
See GEP-23 for the full specification, the
desugaring rules, the carrier-shape requirements, and the relationship
to for await / parallel collections / actors and agents.
Type Checking Extensions
Groovy’s type checking is extensible, allowing you to strengthen
type checking beyond what the standard checker provides.
Groovy 6 adds support for parameterized type checking extensions
(GROOVY-11908),
allowing extensions to accept configuration arguments
directly in the @TypeChecked
annotation string.
Several new type checking extensions take advantage of this capability.
The new checkers below all live in the groovy.typecheckers package.
NullChecker
The NullChecker extension
(GROOVY-11894)
validates code annotated with @Nullable, @NonNull, and
@MonotonicNonNull annotations, detecting null-related errors
at compile time. It recognises these annotations by simple name
from any package (JSpecify, JSR-305, JetBrains, SpotBugs,
Checker Framework, or your own):
@TypeChecked(extensions = 'groovy.typecheckers.NullChecker')
int safeLength(@Nullable String text) {
if (text != null) {
return text.length() // ok: null guard
}
return -1
}
assert safeLength('hello') == 5
assert safeLength(null) == -1Without the null guard, dereferencing a @Nullable parameter
produces a compile-time error.
The checker also recognises safe navigation, early-exit patterns,
@NullCheck, and @MonotonicNonNull for lazy initialisation.
Strict mode: no annotations needed
Passing strict: true extends the checker with flow-sensitive analysis
that detects null issues even in completely unannotated code — no @Nullable, no @NonNull, no special types:
@TypeChecked(extensions = 'groovy.typecheckers.NullChecker(strict: true)')
static main(args) {
def x = null
x.toString() // compile error: 'x' may be null
def y = null
y = 'hello'
assert y.toString() == 'hello' // ok: reassigned non-null
}The checker tracks nullability through assignments and control flow,
catching potential dereferences that would otherwise surface only at runtime.
This is also an example of parameterized type checking extensions in action — the strict: true argument is passed directly in the extension string.
See also the NullChecker blog post for a detailed walkthrough.
CombinerChecker
The parallel Collection reductions (sumParallel, injectParallel) split,
reorder, and recombine their input. That is only correct when the combining
function is associative — combine(a, combine(b, c)) must equal
combine(combine(a, b), c) — and, for the seeded injectParallel, when the
seed is an identity. A non-associative combiner (subtraction, division)
compiles and runs but produces a different, non-deterministic result depending
on how the work was partitioned — among the hardest bug classes to detect by
testing alone.
The CombinerChecker extension
(GROOVY-12013)
verifies at compile time that combiners reaching these methods carry the
contract. A combiner declares it with the new
@Associative and
@Reducer annotations (@Reducer also names an
identity element via zero()):
import groovy.transform.Associative
class Maths {
@Associative static int add(int a, int b) { a + b }
}
@TypeChecked(extensions = 'groovy.typecheckers.CombinerChecker')
def reduce() {
[1, 2, 3].injectParallel(0, Maths.&add) // ok: declared @Associative
[1, 2, 3].injectParallel(0) { a, b -> a + b } // ok: lenient, associative
[1, 2, 3].injectParallel(0) { a, b -> a - b } // compile error: non-associative
}The default (lenient) mode flags only high-confidence problems — a
non-associative operator (-, /, %, **) applied directly to the
combiner parameters, or an injectParallel seed that contradicts a
@Reducer’s declared `zero(). The parameterized strict mode additionally
requires the combiner to be a method reference to an annotated method. The
checker also recognises Monoid/Semigroup carriers from external libraries,
and covers java.util.stream reduce overloads. Since associativity is
undecidable in general, this is a conservative, false-positive-averse safety
net rather than a proof; the annotations assert the law and are intended to be
backed by tests. Because the law is fully specified by the annotation itself,
those tests are machine-actionable — a property-based
test asserting combine(a, combine(b, c)) == combine(combine(a, b), c) (plus
the identity law for @Reducer) can be auto-derived by tooling or an AI agent
directly from the declaration.
Feature summary
| Feature | Description | Ticket |
|---|---|---|
Parameterized extensions |
Type checking extensions can accept configuration arguments directly
in the |
|
|
Compile-time null safety. Validates |
|
|
Flow-sensitive null analysis without annotations. Tracks variables
assigned |
|
|
Recognises null-safety facts from |
|
Verifies |
||
Enforces functional purity at compile time. Verifies |
||
Verifies combiners passed to |
Designed for Human and AI Reasoning
A key design goal for Groovy 6 is making code easier to reason about — for both humans and AI. Several of the contract and type checking features described above work together to achieve this: @Modifies and @Pure declare what changes (and what doesn’t), @Requires and @Ensures declare what holds before and after, and type checking extensions like ModifiesChecker and PurityChecker verify these declarations at compile time. The combined effect is that each method becomes a self-contained specification — you can reason about what it does without reading its body.
Consider this annotated class, verified by both ModifiesChecker
and PurityChecker:
@TypeChecked(extensions = ['groovy.typecheckers.ModifiesChecker',
'groovy.typecheckers.PurityChecker'])
@Invariant({ balance >= 0 })
class Account {
BigDecimal balance = 0
List<String> log = []
@Requires({ amount > 0 })
@Ensures({ balance == old.balance + amount })
@Modifies({ [this.balance, this.log] })
void deposit(BigDecimal amount) {
balance += amount
log.add("deposit $amount")
}
@Requires({ amount > 0 && amount <= balance })
@Ensures({ balance == old.balance - amount })
@Modifies({ [this.balance, this.log] })
void withdraw(BigDecimal amount) {
balance -= amount
log.add("withdraw $amount")
}
@Pure
BigDecimal available() { balance }
}When analyzing a sequence of calls:
account.deposit(100)
account.withdraw(30)
def bal = account.available()With annotations, each call is a self-contained specification — 3 linear reasoning steps:
-
deposit(100):@Requiresmet (100 > 0),@Ensuresgivesbalance == old + 100,@Modifiesproves onlybalanceandlogchanged -
withdraw(30):@Requiresmet (30 > 0, 30 within balance),@Ensuresgivesbalance == 100 - 30 = 70,@Modifiesproveswithdrawdidn’t undo the deposit -
available():@Pureproves no side effects — just returnsbalance(70)
Without annotations, the analyzer must read every method body,
verify what each one modifies (2 fields × 3 calls = 6 "did this change?"
questions), re-verify earlier state after later calls, and check whether
available() has hidden side effects.
In general, this grows as O(fields × calls × call_depth) — which is where AI starts hallucinating or saying
"I’d need to see more context."
| What must be verified | With annotations | Without annotations |
|---|---|---|
Does |
No — |
Must read body + all callees |
Does |
No — |
Must read both method bodies |
Is |
Yes — |
Must read body, check for overrides |
What is |
Derive from |
Replay all mutations manually |
Can |
Check |
Must analyze all pairs for interference |
The type checkers provide the compile-time guarantee that these
annotations are truthful: ModifiesChecker verifies method bodies
only modify declared fields, and PurityChecker verifies @Pure
methods have no side effects. Without that guarantee, annotations
would be just comments — claims you’d still need to verify by
reading the code.
Reading and verification are two of the payoffs; a third is that the
same declarations are machine-actionable. Because @Pure, @Modifies,
@Requires/@Ensures, @Invariant/@Decreases and the algebraic
@Associative/@Reducer are both
machine-readable and compiler-enforced, tooling and AI skills can build
on them rather than guess — deriving tests and documentation, driving or
validating refactorings and migrations, and treating each verified
contract as a guardrail an agent must not cross. The algebraic annotations
are an especially direct case: an @Associative method fully specifies a
property — combine(a, combine(b, c)) == combine(combine(a, b), c) — so an AI agent or skill can mechanically generate the property-based test
that backs the assertion (and, for @Reducer, the matching identity law)
rather than infer intent from the body. The compile-time
guarantee is what makes this safe: a skill can rely on a @Pure method
being pure because PurityChecker proved it, not because a comment
claimed it. A Groovy 6 codebase is therefore not only easier for humans
and AI to read — it is a verified specification they can reliably
build on.
val Keyword for Final Declarations
Groovy 6 adds val as a contextual keyword for declaring final
variables and fields
(GROOVY-9308,
GEP-16).
val complements the existing var keyword: val declares an
immutable binding (equivalent to final def), while var continues
to declare a mutable one. The shape and naming will be familiar to
anyone who has seen Kotlin or Scala code declaring read-only (immutable) variables.
val name = 'Groovy' // equivalent to: final def name = 'Groovy'
val list = [1, 2, 3] // shallow finality — list contents may still mutate
list << 4 // OK
name = 'Other' // compile error: cannot assign to final variableLike var, val is contextual — it remains usable as a variable
name, method name, map key, or property name. Existing code such as
def val = 1, obj.val, and [val: 42] continues to work
unchanged. val is rejected only where it would be ambiguous with a
type (for example, as a method return type or in a class val {}
declaration), mirroring the restrictions already in place for var.
When statically type-checking code, val carries the same type
inference rules as var:
val x = 42 // inferred as int
val s = 'hello' // inferred as String
val list = [1, 2, 3] // inferred as ArrayList<Integer>A small number of pre-existing parser edge cases around var apply
equally to val — chiefly a field named val (or var) declared
immediately before a method or constructor, and val as Type cast
expressions. For codebases that need more time to migrate, a
-Dgroovy.val.enabled=false system property disables the keyword
entirely, lexing val as a plain identifier
(GROOVY-11994).
See GEP-16 for the full specification, including the migration flag and the complete list of edge cases.
Multi-assignment Destructuring
Groovy 6 extends def (…) multi-assignment with rest bindings and
map-style key destructuring
(GROOVY-11964).
Three idioms common in modern languages but previously unavailable in
Groovy are now supported. The extension is strictly additive — every program valid in Groovy 4 / 5 compiles with identical semantics — because each new shape uses an unparseable token sequence in the
existing grammar.
See GEP-20 for the full specification.
Tail rest binding
A trailing *ident captures the remaining elements:
def (h, *t) = [1, 2, 3, 4]
assert h == 1
assert t == [2, 3, 4]
def (a, b, c, *rest) = 'hello'
assert a == 'h' && b == 'e' && c == 'l'
assert rest == 'lo' // String slice — type tracks the RHSThe rest binding works against any RHS supporting either
getAt(IntRange) or iterator(). The compiler picks one of three
lowerings — a Stream rewrap that keeps lazy pipelines lazy, an
getAt(IntRange) slice (whose return type drives the rest binder’s
type), or an iterator fallback that supports unbounded sources without
materialising them:
// Lazy iterator — rest stays lazy
def naturals = (1..Integer.MAX_VALUE).iterator()
def (first, *more) = naturals
assert first == 1
assert more.next() == 2 && more.next() == 3
// Stream — pipeline preserved, sequential
def (header, *body) = Stream.of('# title', 'line 1', 'line 2')
assert header == '# title'
assert body.collect(Collectors.toList()) == ['line 1', 'line 2']Rest binding in head and middle positions
*ident in non-tail position lowers via indexed access against a
sized, indexable RHS:
def (*front, last) = [1, 2, 3, 4]
assert front == [1, 2, 3]
assert last == 4
def (l, *middle, r) = [1, 2, 3, 4, 5]
assert l == 1 && r == 5
assert middle == [2, 3, 4]
def (a, b, *m, y, z) = 1..6
assert a == 1 && b == 2 && y == 5 && z == 6
assert m == [3, 4]Map-style destructuring
key: ident pairs in the declarator list bind via property access
(map keys, JavaBean getters, or getProperty via the MOP):
def person = [name: 'Alice', age: 30, role: 'admin']
def (name: n, age: a) = person
assert n == 'Alice' && a == 30
// Type ascriptions pin or coerce binding types
def (name: String fullName, age: int years) = person
// Works on JavaBeans too
def (year: y, month: m) = Calendar.instanceType ascriptions on rest binders
The rest binder may carry a type ascription, mirroring the existing positional form:
def (h, List<Integer> *t) = [1, 2, 3, 4]
def (c, String *cs) = 'hello'
def (l, List<Integer> *m, r) = [1, 2, 3, 4, 5]def / var binder markers and modifier propagation
For symmetry with switch case patterns and bracket-form declarations,
def and var may appear before any binder; they are equivalent to
omitting a type. Modifiers on the outer declaration propagate to every
binder (including rest and map-style):
def (var a, var b) = [1, 2] // same as: def (a, b) = [1, 2]
def (def a, var b, int c) = [1, 2, 3] // mix and match
final (a, *t) = [1, 2, 3] // both `a` and `t` are final
final (name: n, age: a) = [name: 'A', age: 1] // both `n` and `a` are final_ for unwanted slots
The "discard" convention, e.g. def (_, y, m) = Calendar.instance,
applies uniformly across every new form. _ is a regular identifier
throughout — no wildcard semantics, no special parser node:
def (_, *t) = [1, 2, 3] // _ binds to the head
def (h, *_) = [1, 2, 3] // _ binds to the rest
def (*_, last) = [1, 2, 3] // _ binds to the front
def (l, *_, r) = [1, 2, 3, 4, 5] // _ binds to the middle
def (name: _, age: a) = [name: 'A', age: 30] // _ binds to the name slotCompound Assignment Operator Overloading
Groovy 6 lets classes overload the compound assignment operators
(+=, -=, *=, …) independently from their base operators
(GROOVY-11970,
GEP-15).
Historically, x += y always desugared to x = x.plus(y) — creating a
new value and rebinding the variable. That forced mutable types into
inefficient create-and-reassign patterns and made compound assignment
unavailable on final fields and variables.
A class can now define a dedicated *Assign method (plusAssign,
minusAssign, multiplyAssign, and so on). When such a method is
resolved on the receiver, the operator mutates the receiver in place
instead of reassigning the LHS:
class Accumulator {
int total = 0
void plusAssign(int n) { total += n } // mutate in place
Accumulator plus(int n) { new Accumulator(total: total + n) } // create new
}
def acc = new Accumulator()
acc += 5 // calls plusAssign — no reassignment
assert acc.total == 5Because no reassignment occurs when Assign is used, compound
assignment now works on final fields and variables under
@CompileStatic/@TypeChecked whenever a matching *Assign method
exists on the receiver type. For property LHS, the setter is *not
invoked. The expression value of x op= y is the (mutated) x, not the
return value of *Assign.
The change is strictly additive: if no *Assign method matches, the
legacy x = x.op(y) desugar still applies, so existing code keeps
working. Resolution is direct under static compilation and via the MOP
in dynamic code; *Assign methods are also discoverable as extension
methods or categories. Names can be remapped via
@OperatorRename (e.g.
@OperatorRename(plusAssign='addInPlace')).
The full set of compound assignment operators and their corresponding
*Assign methods (with op fallbacks) is:
| Operator | Assign method | Fallback method |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
See GEP-15 for the full specification.
Nested copyWith for @Immutable and Records
@Immutable and
@RecordType have long offered an opt-in
copyWith (copyWith=true) that returns a new instance with selected
properties replaced. Groovy 6 extends it to nested updates across an
immutable object graph
(GROOVY-12015).
A map key may now be a dotted nested path. Untouched branches are reused
rather than rebuilt, so structural sharing (and is identity) is preserved
transitively:
@Immutable(copyWith = true) class Address { String city, zip }
@Immutable(copyWith = true) class Person { String name; Address address }
def p = new Person('Alice', new Address('NYC', '10001'))
def q = p.copyWith('address.city': 'Boston')
assert q.address.city == 'Boston'
assert q.address.zip == '10001' // carried over unchanged
assert q.name == 'Alice'Every node on the path must itself provide copyWith(Map) (i.e. be declared
with copyWith=true); otherwise a clear error is raised.
A transactional block form is also generated as sugar over the map form.
Inside the block, old is the original (pre-state) object — aligning with
old in @Ensures/@Contract — so new values can be derived from it, and
prop.modify { } is shorthand for the transform-this-same-field case
(e.g. loginCount.modify { it + 1 }):
def r = p.copyWith {
name = 'Bob' // plain set
address.city = old.address.city.reverse() // derive from pre-state
}
assert r.name == 'Bob'
assert r.address.city == 'NYC'.reverse()
assert p.copyWith { }.is(p) // empty block: identityThe same nested map and block forms work for record-in-record graphs and
mixed @Immutable/@RecordType hierarchies.
Stabilised features
-
Sealed classes, interfaces and traits — introduced as an incubating feature in Groovy 4.0 and stabilised through the 5.x line — are promoted out of incubation in Groovy 6.0 (GROOVY-12008). The full specification for sealed types is in GEP-13: Sealed Types, which was revised alongside the 6.0 graduation.
-
The
groovy-tomlmodule — introduced as an incubating module in Groovy 4.0 — is promoted out of incubation in Groovy 6.0 (GROOVY-12010). Its public API is now covenanted and subject to binary-compatibility checks. -
The
groovy-contractsmodule is promoted out of incubation in Groovy 6.0 (GROOVY-12038). Its core@Requires/@Ensures/@InvariantAPI is now stable; the newest additions described in Groovy-Contracts Enhancements that build on still-incubating infrastructure — loop-level@Invariant/@Decreasesand@Modifiesframe conditions — remain incubating for this release. -
The
RegexCheckerandFormatStringCheckertype-checking extensions are promoted out of incubation in Groovy 6.0 (GROOVY-12039). -
The macro framework — the
@Macroannotation and related classes — is promoted out of incubation in Groovy 6.0 (GROOVY-12029). -
The
PropertyHandlerSPI for property-style AST transforms is promoted out of incubation in Groovy 6.0 (GROOVY-12030). -
JavaShellis promoted out of incubation in Groovy 6.0 (GROOVY-12026) and gains a newcompileAllTomethod (GROOVY-12025).
Extension method additions and improvements
Groovy provides over 2000 extension methods to 150+ JDK classes to enhance JDK functionality, with new methods added in Groovy 6.
groupByMany — multi-key grouping
Several variants of groupByMany
(GROOVY-11808)
exist for grouping lists, arrays, and maps of items by multiple keys — similar to Eclipse Collections' groupByEach and a natural fit for
many-to-many relationships that SQL handles with GROUP BY.
The most common form takes a closure that maps each item to a list of keys:
var words = ['ant', 'bee', 'ape', 'cow', 'pig']
var vowels = 'aeiou'.toSet()
var vowelsOf = { String word -> word.toSet().intersect(vowels) }
assert words.groupByMany(s -> vowelsOf(s)) == [
a:['ant', 'ape'], e:['bee', 'ape'], i:['pig'], o:['cow']
]For maps whose values are already lists, a no-args variant groups keys by their values:
var availability = [
'🍎': ['Spring'],
'🍌': ['Spring', 'Summer', 'Autumn', 'Winter'],
'🍇': ['Spring', 'Autumn'],
'🍒': ['Autumn'],
'🍑': ['Spring']
]
assert availability.groupByMany() == [
Winter: ['🍌'],
Autumn: ['🍌', '🍇', '🍒'],
Summer: ['🍌'],
Spring: ['🍎', '🍌', '🍇', '🍑']
]A two-closure form also exists for transforming both keys and values. See the groupByMany blog post for more examples including Eclipse Collections interop.
Process handling
waitForResult replaces the manual stream/exit-code dance with a single call
(GROOVY-11901):
var result = 'echo Hello World'.execute().waitForResult()
assert result.output == 'Hello World\n'
assert result.exitValue == 0
// With timeout
var result = 'sleep 60'.execute().waitForResult(5, TimeUnit.SECONDS)Asynchronous file I/O
The groovy-nio module adds async file operations on Path that return
CompletableFuture results
(GROOVY-11902).
These compose naturally with Groovy 6’s async/await:
import java.nio.file.Path
// Read two files concurrently
def a = Path.of('config.json').textAsync
def b = Path.of('data.csv').textAsync
def (config, data) = await(a, b)Regex group extraction
Capturing regex groups was always possible via Matcher (m[0][1] and
friends), but the common case — pull a few named pieces out of a string — meant juggling group indices and guarding against a non-match. findGroups
returns the full match followed by each capture group as a List, so it
pairs naturally with multi-assignment. This isn’t new capability; it just
removes the Matcher boilerplate from one very common case
(GROOVY-11958):
def semver = /(\d+)\.(\d+)\.(\d+)(?:-(.+))?/
def (_, major, minor, patch, qualifier) = '6.0.0-beta-2'.findGroups(semver)
assert [major, minor, patch, qualifier] == ['6', '0', '0', 'beta-2']
// optional qualifier absent: multi-assignment pads with null,
// so the same destructuring works whether or not it matched
def (_all, ma, mi, pa, q) = '4.0.28'.findGroups(semver)
assert [ma, mi, pa, q] == ['4', '0', '28', null]Sliding pairs and consecutive runs
Two new GDK methods cover common "look at neighbours" list operations that previously needed index juggling or a manual fold (GROOVY-12016).
zipWithNext pairs each element with its successor, optionally combining
each pair — handy for deltas, ratios, or detecting transitions:
assert [1, 2, 3, 4].zipWithNext() == [[1, 2], [2, 3], [3, 4]]
// successive deltas via the combiner form
assert [10, 13, 12, 18].zipWithNext { a, b -> b - a } == [3, -1, 6]groupConsecutive splits an iterable into maximal runs — by equality, by a
key function, or by an adjacency predicate (note: only consecutive equal
keys group together, unlike groupBy):
assert [1, 1, 2, 2, 2, 3, 1].groupConsecutive() == [[1, 1], [2, 2, 2], [3], [1]]
assert ['apple', 'avocado', 'banana', 'cherry', 'citrus', 'date']
.groupConsecutive { it[0] } == [['apple', 'avocado'], ['banana'], ['cherry', 'citrus'], ['date']]Both have lazy Iterator variants and array overloads, so they compose with
other sequence operations without materialising intermediates.
Allocation-free higher-order methods (java.util.function overloads)
Many of Groovy’s higher-order extension methods now have overloads that accept
java.util.function SAM types — Predicate, Function, Consumer,
BiPredicate, BiFunction, and friends — directly, instead of requiring a
Closure wrapper
(GROOVY-12034,
GROOVY-12054). Passing a
lambda or method reference straight through avoids the per-call Closure
allocation — "fat-free" — and improves interop with Java APIs that already
hand you java.util.function values. The standard overloads mirror the
existing Closure forms one-for-one, covering each/eachWithIndex,
collect/collectEntries, groupBy, inject, any/every,
find/findAll, count, and the lazy collecting/findingAll iterator
variants.
import java.util.function.Predicate
import java.util.function.Function
Predicate<Integer> even = n -> n % 2 == 0
Function<Integer, Integer> square = n -> n * n
assert [1, 2, 3, 4].findAll(even) == [2, 4]
assert [1, 2, 3].collect(square) == [1, 4, 9]A companion curryWith helper (in org.apache.groovy.util.Lambdas, and in
org.apache.groovy.util.Closures for hybrid results usable as both a
Closure and a java.util.function type) right-partials a two-argument SAM
by fixing its second argument, so a shared BiPredicate/BiFunction can be
reused across calls without a capturing closure:
import static org.apache.groovy.util.Closures.curryWith
import java.util.function.BiPredicate
BiPredicate<Integer, Integer> divisibleBy = (n, d) -> n % d == 0
assert [1, 2, 3, 4, 5, 6].findAll(curryWith(divisibleBy, 2)) == [2, 4, 6]A matching set of incubating …(self, BiPredicate/BiFunction, param)
overloads bake this right-curry in directly — list.find(condition, param)
is equivalent to list.find(curryWith(condition, param)) — covering
collect/collecting, find/findAll/findingAll, any/every, and
count:
def divisibleBy = { n, d -> n % d == 0 }
assert [1, 2, 3, 4, 5, 6].findAll(divisibleBy, 2) == [2, 4, 6] // incubatingOther new extension methods
| Method | Description | Ticket |
|---|---|---|
|
Check whether elements of an Iterable, Iterator, array, or Map
are in sorted order. Supports natural ordering, |
|
|
Named parameters for process configuration: |
|
|
Convert a String, String array, or List into a |
|
|
Create native OS pipelines from a list of commands via
|
|
|
Register a closure to execute asynchronously when a process terminates.
|
|
|
Asynchronous file reading on |
|
|
Asynchronous file writing on |
|
|
Lazy |
|
|
Return a list of all matches of a regex within a |
|
|
Constrain a |
|
|
Return the receiver if it satisfies the predicate, otherwise |
|
|
Explicit-mutability accumulators for |
Selectively Disabling Extension Methods
The groovy.extension.disable system property has been enhanced
(GROOVY-11892),
to allow finer-grained control over which
Groovy extension methods are disabled. Previously, setting
-Dgroovy.extension.disable=groupBy would disable all overloads
of groupBy. Now, specific overloads can be targeted by
receiver type or full parameter signature:
| Syntax | Effect |
|---|---|
|
Disables all |
|
Disables only the overload for |
|
Disables all overloads of both methods |
Type names can be simple (Set) or fully qualified (java.util.Set).
This is particularly useful when integrating with libraries like
Eclipse Collections that define
methods with the same name as Groovy’s extension methods but return
different types. For example, Groovy’s groupBy returns lists or maps
from the standard collections library, but Eclipse Collections' groupBy returns a Multimap.
By disabling the Groovy overload only for Lists,
we can still use Groovy’s groupBy on java.util.Map instances.
// disable groupBy only for Lists
// (well, all iterables but only for the Closure variant)
// -Dgroovy.extension.disable=groupBy(Iterable,Closure)
var fruits = Lists.mutable.of('🍎', '🍌', '🍎', '🍇', '🍌')
// Eclipse Collections groupBy → returns a Multimap
assert fruits.groupBy { it } ==
Multimaps.mutable.list.empty()
.withKeyMultiValues('🍎', '🍎', '🍎')
.withKeyMultiValues('🍌', '🍌', '🍌')
.withKeyMultiValues('🍇', '🍇')
// Groovy's groupBy still works on Maps
def result = [a:1,b:2,c:3,d:4].groupBy { it.value % 2 }
assert result == [0:[b:2, d:4], 1:[a:1, c:3]]Customisable Object Display with groovyToString
Groovy 6 introduces a groovyToString() protocol
(GROOVY-11893)
that lets classes control how their instances appear in string
interpolation, println, collection formatting, and other display contexts.
When a class defines a groovyToString() method returning String,
Groovy uses it instead of toString() for display purposes:
class Foo {
String toString() { 'some foo' }
String groovyToString() { 'some bar' }
}
assert "${new Foo()}" == 'some bar'
assert [foo: new Foo()].toString() == '[foo:some bar]'Groovy also provides built-in groovyToString extension methods for
collections, maps, ranges, and primitive arrays, giving them their
familiar Groovy formatting (e.g. [1, 2, 3] for int[] rather than
Java’s [I@hashcode). These can be selectively disabled using the
groovy.extension.disable system property if needed.
GINQ Enhancements
groupby … into
GINQ’s groupby clause now supports an into keyword
(GROOVY-11915)
that binds each group to a named variable with aggregate access:
GQ {
from n in [1, 11, 111, 8, 80]
groupby (n % 2 == 0 ? 'even' : 'odd') into g
select g.key, g.count() as count, g.sum(n -> n) as sum, g.toList() as numbers
}+------+-------+-----+--------------+ | key | count | sum | numbers | +------+-------+-----+--------------+ | even | 2 | 88 | [8, 80] | | odd | 3 | 123 | [1, 11, 111] | +------+-------+-----+--------------+
Set operators
SQL-style set operators
(GROOVY-11919)
for combining query results: union, intersect, minus, and unionall:
def java = ['Alice', 'Bob', 'Carol']
def groovy = ['Bob', 'Carol', 'Dave']
assert GQL {
from n in java select n
union
from n in groovy select n
} == ['Alice', 'Bob', 'Carol', 'Dave']See the GINQ user guide for the full set of clauses and operators.
CSV Module (incubating)
Groovy 6 adds a new groovy-csv module
(GROOVY-11923)
for reading and writing CSV (RFC 4180) data.
Classes live in the groovy.csv package.
Reading CSV
CsvSlurper parses CSV text into a list of maps, keyed by column headers:
def csv = new CsvSlurper().parseText('name,age\nAlice,30\nBob,25')
assert csv.size() == 2
assert csv[0].name == 'Alice'
assert csv[0].age == '30'The separator and quote characters can be customised via fluent setters,
and quoted fields follow RFC 4180 rules (embedded commas, newlines, and
doubled quotes). Set useHeader = false to treat the first row as data
and key rows by auto-generated column names. Reader/InputStream/File/Path
overloads of parse are provided alongside parseText.
Writing CSV
CsvBuilder converts collections of maps to CSV:
def data = [
[name: 'Alice', age: 30],
[name: 'Bob', age: 25]
]
def csv = CsvBuilder.toCsv(data)
assert csv.contains('name,age')
assert csv.contains('Alice,30')Typed parsing and writing
When Jackson is on the classpath, CsvSlurper can parse CSV directly
into typed objects, and CsvBuilder can write typed objects to CSV.
This is particularly useful for CSV since all values are strings — Jackson handles conversion to numeric, date, and other types automatically:
class Sale {
String customer
BigDecimal amount
}
def sales = new CsvSlurper().parseAs(Sale, 'customer,amount\nAcme,1500.00\nGlobex,250.50')
assert sales[0].customer == 'Acme'
assert sales[0].amount == 1500.00See the Processing CSV user guide for the full API and configuration options.
Typed Parsing and Writing Across Format Modules
Groovy 6 brings typed parsing support across all data format modules, giving a consistent way to convert structured data into typed objects. Given a target class:
class ServerConfig { String host; int port; boolean debug }Each format can parse directly into it:
// JSON — as coercion (no extra deps)
def config = new JsonSlurper().parseText(json) as ServerConfig
// TOML — Jackson-backed parseTextAs
def config = new TomlSlurper().parseTextAs(ServerConfig, toml)
// XML — Jackson-backed parseTextAs
def config = new XmlParser().parseTextAs(ServerConfig, xml)| Format | Typed Parsing | Typed Writing |
|---|---|---|
JSON |
JsonSlurper + |
JsonOutput |
CSV (GROOVY-11923) |
CsvSlurper |
CsvBuilder |
TOML (GROOVY-11925) |
TomlSlurper |
TomlBuilder |
YAML (GROOVY-11926) |
YamlSlurper |
YamlBuilder |
XML (see XML Processing Improvements) (GROOVY-11927) |
XmlParser |
— |
|
Note
|
For CSV, TOML, YAML, and XML, the The typed parse/write paths for CSV, TOML and YAML support |
XML Processing Improvements
The groovy-xml module gains secure-by-default XML processing,
StAX streaming helpers, named-parameter construction for parsers,
and a richer XmlUtil.serialize API.
For typed parsing of XML documents into POJOs, see Typed Parsing and Writing Across Format Modules.
Secure-by-default XML processing
XXE attacks, billion-laughs entity expansion, and unintended network
access via external DTDs all stem from JDK XML factories that ship with
permissive defaults. The front-line Groovy parsers — XmlParser,
XmlSlurper, the static
DOMBuilder.parse(…) overloads, and
XmlUtil.newSAXParser — were already secure-by-default. Groovy 6
closes the remaining gaps in XmlUtil.serialize, FactorySupport, and
DOMBuilder.newInstance
(GROOVY-11979,
GROOVY-11981) — see Breaking changes for the per-API migration knobs. A new XML
security chapter in the user guide documents the contract end-to-end.
StAX streaming helpers
Two new XmlUtil methods stream over XML sources without loading the
whole document into memory
(GROOVY-11979):
events(reader) returns a Stream<XMLEvent>, and
streamElements(reader, [namespaceURI,] localName) pulls each matching
subtree as a small DOM Node. Both run on a hardened XMLInputFactory,
so streaming an untrusted feed is safe out of the box.
Combined with the new HttpBuilder, we can fetch a published Groovy pom from Maven Central and extract its license:
import groovy.xml.XmlUtil
import static groovy.http.HttpBuilder.http
def pom = http('https://repo1.maven.org/maven2')
.get('/org/apache/groovy/groovy/5.0.5/groovy-5.0.5.pom').body
def licenses = XmlUtil.streamElements(new StringReader(pom), 'license')
.map { l -> l.getElementsByTagName('name').item(0).textContent }
.toList()
assert licenses == ['The Apache Software License, Version 2.0']The lower-level events API suits counts and scans where a DOM Node
per match would be wasteful — counting <dependency> entries across
both dependencyManagement and dependencies is a single filter:
import javax.xml.stream.events.XMLEvent
def deps = XmlUtil.events(new StringReader(pom))
.filter { it.eventType == XMLEvent.START_ELEMENT &&
it.asStartElement().name.localPart == 'dependency' }
.count()
assert deps == 5Other improvements
| Feature | Description | Ticket |
|---|---|---|
Named-parameter construction |
|
|
|
|
|
Extended JAXP factory access |
FactorySupport now covers all six
JAXP factory types — the existing |
Markdown Module (incubating)
Groovy 6 adds a new optional groovy-markdown module
(GROOVY-11940)
for parsing CommonMark Markdown into a
navigable document model. Classes live in the groovy.markdown
package. A common motivating use case is extracting structured
pieces from LLM output — code blocks by language, sections by
heading, links, and tables — but the module is useful anywhere
Markdown is processed programmatically.
MarkdownSlurper
MarkdownSlurper parses Markdown
text into a MarkdownDocument
backed by nested lists and maps. Each node is a Map with a type
key plus type-specific fields:
def doc = new MarkdownSlurper().parseText('# Hello World')
def h = doc.headings[0]
assert h.level == 1
assert h.text == 'Hello World'The document exposes convenience properties — headings,
codeBlocks, links, tables — that recursively walk the tree,
so nodes nested inside list items or block quotes are still found.
A text property gives a plain-text projection of the whole
document with formatting markers stripped.
Extracting code blocks
Pulling fenced code blocks by language is a common pattern when consuming LLM output:
def doc = new MarkdownSlurper().parseText(md)
def groovySnippets = doc.codeBlocks.findAll { it.lang == 'groovy' }*.textSections
section(headingText) returns the nodes between a given heading
and the next heading of equal or higher level — handy for parsing
structured agent replies:
def doc = new MarkdownSlurper().parseText(md)
def next = doc.section('Next Steps')
assert next[0].type == 'list'
assert next[0].items*.text == ['Item one', 'Item two']Tables (optional)
GFM-style tables are supported when the
org.commonmark:commonmark-ext-gfm-tables jar is on the classpath.
Call enableTables(true) on the slurper and each row comes back as
a Map keyed by header:
def doc = new MarkdownSlurper().enableTables(true).parseText(md)
def rows = doc.tables[0].rows
assert rows[0].name == 'Alice'
assert rows[1].age == '25'Supported node types include heading, paragraph, code_block,
list/list_item, block_quote, link, image, text,
inline_code, emphasis/strong, html_block/html_inline,
thematic_break, line breaks, and (with the GFM extension) table.
See the Processing Markdown user guide for the full node schema and additional examples.
Grape: Dual Engine Support (incubating)
Groovy 6 introduces a major evolution of the Grape dependency management system (GROOVY-11871) by adding a second built-in engine alongside the existing Apache Ivy backend. Both engines expose the same @Grab family of annotations and the Grape facade API, so most existing scripts work unchanged.
Engine comparison
| Aspect | GrapeIvy (default) | GrapeMaven (new) |
|---|---|---|
Backend |
||
Engine class |
|
|
Local cache |
|
|
Configuration file |
|
None — use |
|
Ivy configurations; lists supported (e.g. |
Single Maven scope only |
|
Honoured (cache-only resolution) |
Not honoured |
Version wildcard |
Resolves to Ivy’s |
Resolves to Maven’s |
Both engines respect the grape.root system property for relocating the cache root.
Selecting the engine
When both engines are on the classpath, GrapeIvy is selected by default. To switch to GrapeMaven for a specific invocation:
groovy -Dgroovy.grape.impl=groovy.grape.maven.GrapeMaven yourscript.groovySet the same property in JAVA_OPTS for a global default.
Custom engines via Java SPI
Custom GrapeEngine implementations are
discovered via the standard java.util.ServiceLoader mechanism by
including a jar with a META-INF/services/groovy.grape.GrapeEngine
entry naming the implementation class. See the user guide for the
full registration protocol.
Migration
Most existing @Grab scripts work unchanged with both engines. The
notable differences when moving from GrapeIvy to GrapeMaven:
-
Multi-value
conf:parameters (e.g.conf:['default','optional']) are not supported — GrapeMaven uses a single Maven scope. -
@GrabConfig(autoDownload=false)is not honoured — point@GrabResolverat a local-only repository for similar semantics. -
~/.groovy/grapeConfig.xmlsettings are GrapeIvy-only — register custom repositories via@GrabResolverorGrape.addResolverinstead.
Switching from GrapeMaven back to GrapeIvy is generally straightforward since GrapeIvy’s defaults are more permissive.
See the Grape user guide for the full per-engine specification, custom-engine registration steps, per-engine logging configuration, and detailed migration walkthrough.
Coordinate shorthands for the grape CLI
The grape install command line tool now accepts the same Maven and
Ivy coordinate shorthands as @Grab and the
Grape facade, in addition to its original
positional form
(GROOVY-12004):
grape install com.example foo 1.2.3 # positional (as before)
grape install com.example:foo:1.2.3 # Maven shorthand
grape install com.example:foo:1.2.3:jdk15@zip # Maven shorthand with classifier and extension
grape install com.example#foo;1.2.3 # Ivy shorthandThe static Grape.grab(String) Java API has been broadened along the
same lines: in addition to its existing endorsed-module notation it
now recognises both shorthand forms, dispatching to grab(Map) once
the coordinate has been parsed.
Hardening
Grape resolution has been hardened against several real-world failure modes (GROOVY-12005):
-
Coordinate values containing
..path segments are now rejected (should not contain '..') in both the Ivy and Maven engines, guarding against path traversal in the cache layout (GROOVY-12073). -
A corrupt or truncated JAR (e.g. a CDN
429/partial response) no longer aborts the whole@Grab; extension-method scanning skips the bad JAR with a warning while the remaining artifacts continue to register. -
Strict local-
m2and cached-grapes resolvers reject half-populated POM-only stubs and corrupt artifacts so a poisoned cache entry is re-fetched rather than silently used; a relaxed configuration is available for environments that need the previous lenient behaviour.
Platform Logging
Groovy 6 replaces direct System.err output with the JDK’s
Platform Logging API (java.lang.System.Logger)
for internal errors and warnings
(GROOVY-11886).
This means Groovy’s diagnostic messages can now be controlled
through standard JVM logging configuration.
By default, messages still appear on the console via java.util.logging,
but users can plug in any logging framework (SLF4J, Log4j2, etc.)
by providing a System.LoggerFinder implementation on the classpath.
Configuring logging
Groovy’s command-line tools resolve logging configuration in the following order (first match wins):
-
A file specified via
-Djava.util.logging.config.file=… -
A user configuration at
~/.groovy/logging.properties(auto-discovered by Groovy at startup) -
The JDK default at
$JAVA_HOME/conf/logging.properties
For example, to enable verbose Grape logging, create
~/.groovy/logging.properties with:
handlers = java.util.logging.ConsoleHandler
java.util.logging.ConsoleHandler.level = ALL
groovy.grape.Grape.level = FINELoggers are organized by module (Core, Grape, Ant, Console, GroovyDoc, JSON, Servlet, Swing, Testing) — see the logging guide for the full list of logger names and their levels.
Joint Compilation Stub Improvements (incubating)
This work is specified by GEP-21.
When mixing Groovy and Java sources, Groovy generates Java stubs so
javac can compile Java files that reference Groovy classes.
Historically, those stubs were generated before AST transforms ran, so
members contributed by transforms such as @TupleConstructor,
@Immutable, or @Builder were absent from the stubs and Java code
relying on them failed to compile.
Groovy 6 extends the AST transform framework so that opt-in transforms can contribute member signatures (constructors, methods, fields) to the generated stubs. The change is strictly additive — transforms that do not opt in behave exactly as before (GROOVY-11976).
For example, a Groovy class using @Immutable:
// UserAccount.groovy
@groovy.transform.Immutable
class UserAccount {
String name
int age
}is now visible to Java callers during joint compilation:
// Caller.java
UserAccount user = new UserAccount("alice", 30);A wide range of built-in transforms have been updated to contribute
stubs, including @AutoClone, @AutoImplement, @Bindable, @Builder,
@Delegate, @EqualsAndHashCode, @ExternalizeMethods, @Final,
@Immutable, @IndexedProperty, @InheritConstructors, @Lazy,
@ListenerList, @MapConstructor, @NamedVariant, @RecordType,
@Singleton, @Sortable, @ToString, @TupleConstructor, and
@Vetoable. Custom transforms can opt in via one of three shapes
(annotation attribute, marker interface, or split-transform classes).
See GEP-21 for the full specification.
In addition:
-
Native records now appear as native records in stubs (GROOVY-11974)
-
Static methods declared in Groovy traits are now correctly visible from Java callers during joint compilation (GROOVY-11899)
-
Groovy sealed types now carry the correct
sealed/permits/non-sealeddeclarations in stubs (GROOVY-12008)
JUnit 6 Support
Groovy 6 updates its testing support to include JUnit 6 (GROOVY-11788). JUnit 6 (Jupiter 6.x) is the latest evolution of JUnit, building upon the JUnit 5 platform.
Using JUnit 6 with Groovy
For most users, no special Groovy module is needed — simply add the standard JUnit Jupiter dependencies to your Gradle or Maven project and write tests in Groovy as usual:
// build.gradle
testImplementation 'org.junit.jupiter:junit-jupiter:6.0.3'The groovy-test-junit6 module
The new groovy-test-junit6 module
provides additional capabilities for users who need them:
-
Running individual test scripts — execute a Groovy test file directly as a script without a full build tool setup
-
Conditional test execution annotations — scripting support for JUnit Jupiter’s conditional execution annotations (GROOVY-11887), allowing conditions to be expressed as Groovy scripts
-
@ForkedJvm— runs an annotated test method or class in a freshly forked JVM, with optionalsystemProperties,jvmArgs, andinheritPropertiesattributes. Useful for tests that need a clean process state, an isolated system property, or specific module-access flags (e.g. `--add-opens=…). `inheritPropertiesaccepts exact property names or prefix patterns ending in(e.g. ’spock.'`) and propagates matching properties from the parent JVM to the child — handy when the build (Gradle, Maven) sets a property the forked test still needs (GROOVY-11997). -
@ExpectedToFail— inverts the pass/fail outcome of a test: the test passes when it throws (optionally an exception of a given type or with a message containing a given substring), and fails when it does not. Composes with@ForkedJvmin either declaration order (GROOVY-11997). -
Convenient dependency management — a single dependency that transitively pulls in compatible JUnit 6 libraries
Similarly, the existing groovy-test-junit5 module continues
to provide the same capabilities for JUnit 5 users.
GroovyConsole: Script Arguments
GroovyConsole now supports setting script arguments directly from the UI
(GROOVY-11895).
Previously, users had to manually set args within their script
as a workaround. A new Set Script Arguments option in the Script menu
lets you specify space-separated arguments that are passed to the script.
Groovysh Enhancements
Inline images and charts with /img
The new /img command renders an image inline in the REPL using JLine’s
terminal-graphics support (Sixel, Kitty, or iTerm2 protocols, auto-detected)
(GROOVY-12003).
The argument can be a local file path, an http(s):// URL, or a Groovy
variable reference using the standard $ syntax:
groovy> /img chart.png
groovy> /img --width=80 https://example.com/diagram.png
groovy> img = new java.awt.image.BufferedImage(200, 100, 1)
groovy> /img $imgWhen the argument resolves to a Groovy value, /img accepts a
BufferedImage or RenderedImage directly, anything with a
createBufferedImage(int, int) or toBufferedImage(int, int) method
(duck-typed — no compile-time dependency), or a javax.swing.JComponent
that is laid out and painted at the requested size. This means popular
charting libraries can be rendered in the REPL without saving to a file
first. JFreeChart matches the createBufferedImage shape, Smile’s
Figure matches toBufferedImage, Smile’s Canvas/MultiFigurePane
and Orson Charts' Chart3DPanel match the JComponent path, and
XChart’s BitmapEncoder.getBufferedImage(chart) returns a plain
BufferedImage. For example, a JFreeChart bar chart:
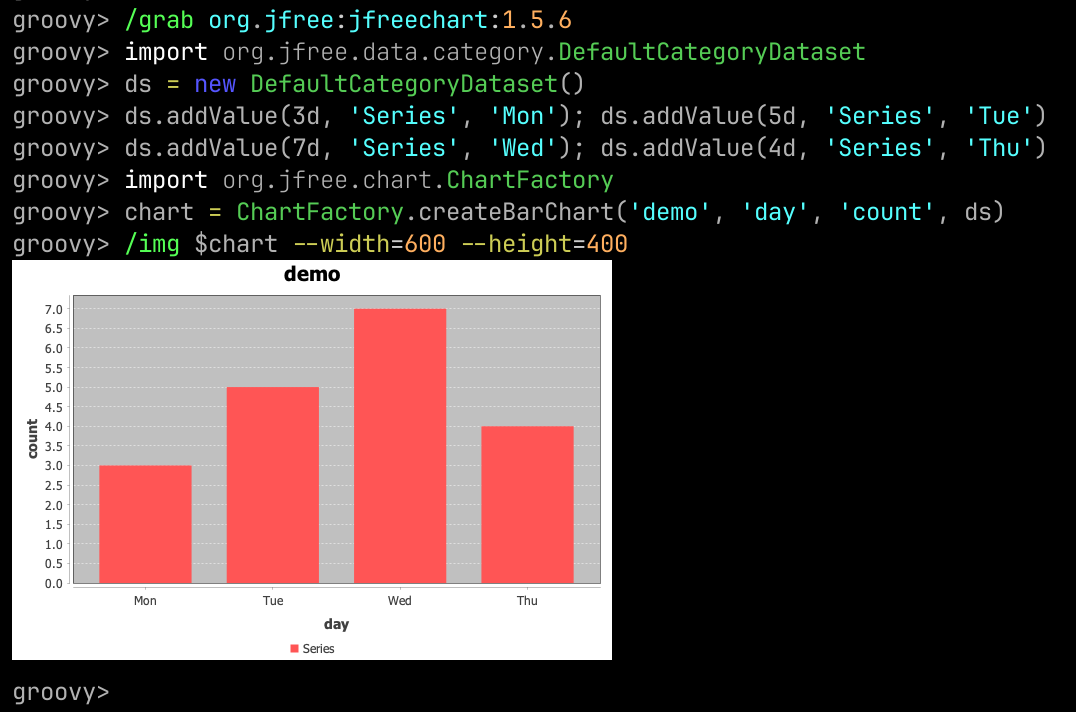
Or feeding CSV through the existing /slurp command into an XChart
line plot:
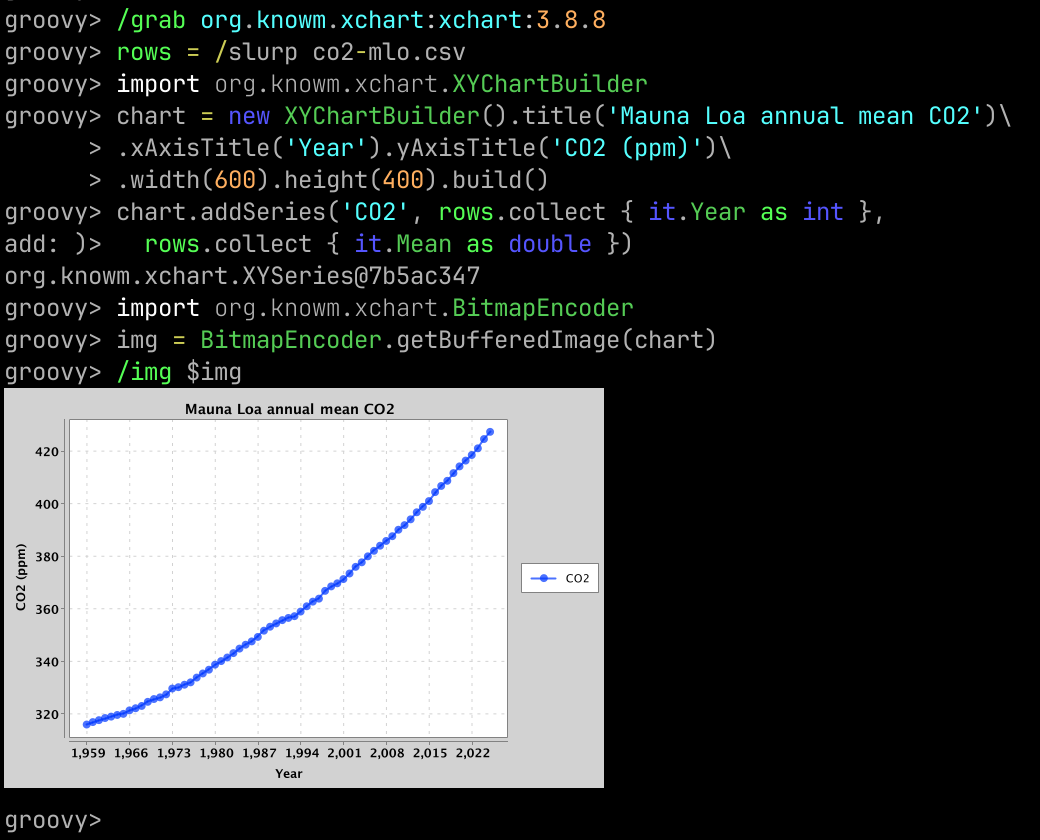
The --width and --height options are in terminal character cells for
raw-pixel inputs and in source-image pixels for inputs that generate the
image at the requested size; aspect ratio is preserved by default. If
the active terminal doesn’t speak a supported graphics protocol (common
cases: macOS Terminal.app, VS Code’s built-in terminal, JetBrains
terminals, plain Windows console), /img prints a [image: WxH, label]
summary instead — pass --gui to open a Swing window with the image
regardless. The command requires the java.desktop module at runtime;
on a JVM where that module is unavailable, /img is not registered.
Markdown support for /slurp
The /slurp command — a shortcut for parsing files into shared
variables using Groovy’s various slurpers (JSON, XML, YAML, CSV, TOML,
properties) — now also handles Markdown
(GROOVY-12002).
Files with .md or .markdown extensions are routed through the new
MarkdownSlurper from groovy-markdown (when it is on the
classpath), yielding a MarkdownDocument that exposes structured
elements — headings, code blocks, links, tables — via the iterator and
convenience properties documented in that module. Combined with /img
above, this enables short pipelines from Markdown reports into rendered
charts directly in the REPL.
Case-insensitive syntax-highlight names
Highlight-style names supplied to /print -s <FORMAT> (and the
/highlighter switch) are now resolved case-insensitively, so json,
JSON, and Json all select the same nanorc grammar
(GROOVY-12018).
Theming Improvements
To match recent theming improvements to the Groovy website — which gained light, dark, and "follow system" options earlier in the year — Groovy 6 brings consistent light/dark/custom theming to its documentation tooling and to GroovyConsole.
Theming is more than visual polish or matching personal preference: it is also an accessibility improvement. Readers with light sensitivity, low-vision users running high-contrast palettes, and anyone working in a low-light environment all benefit from a tool surface that respects the system colour scheme rather than forcing one on them.
GroovyDoc
GroovyDoc gained a -theme flag controlling the output palette
strategy
(GROOVY-11947):
-
auto(default) — follow the reader’s OSprefers-color-scheme. Both palettes are emitted; the browser picks at view time. -
light/dark— lock the output to a single palette regardless of OS preference.
The default stylesheet has been refactored around semantic CSS
custom properties (--fg, --bg, --link, --bg-panel, etc.), so
author stylesheets supplied via --add-stylesheet can reference the
same tokens and become theme-aware automatically — the same hook
that enables fully custom palettes. When Prism.js syntax
highlighting is enabled, the highlight theme swaps in sync with the
page palette
(GROOVY-11946).
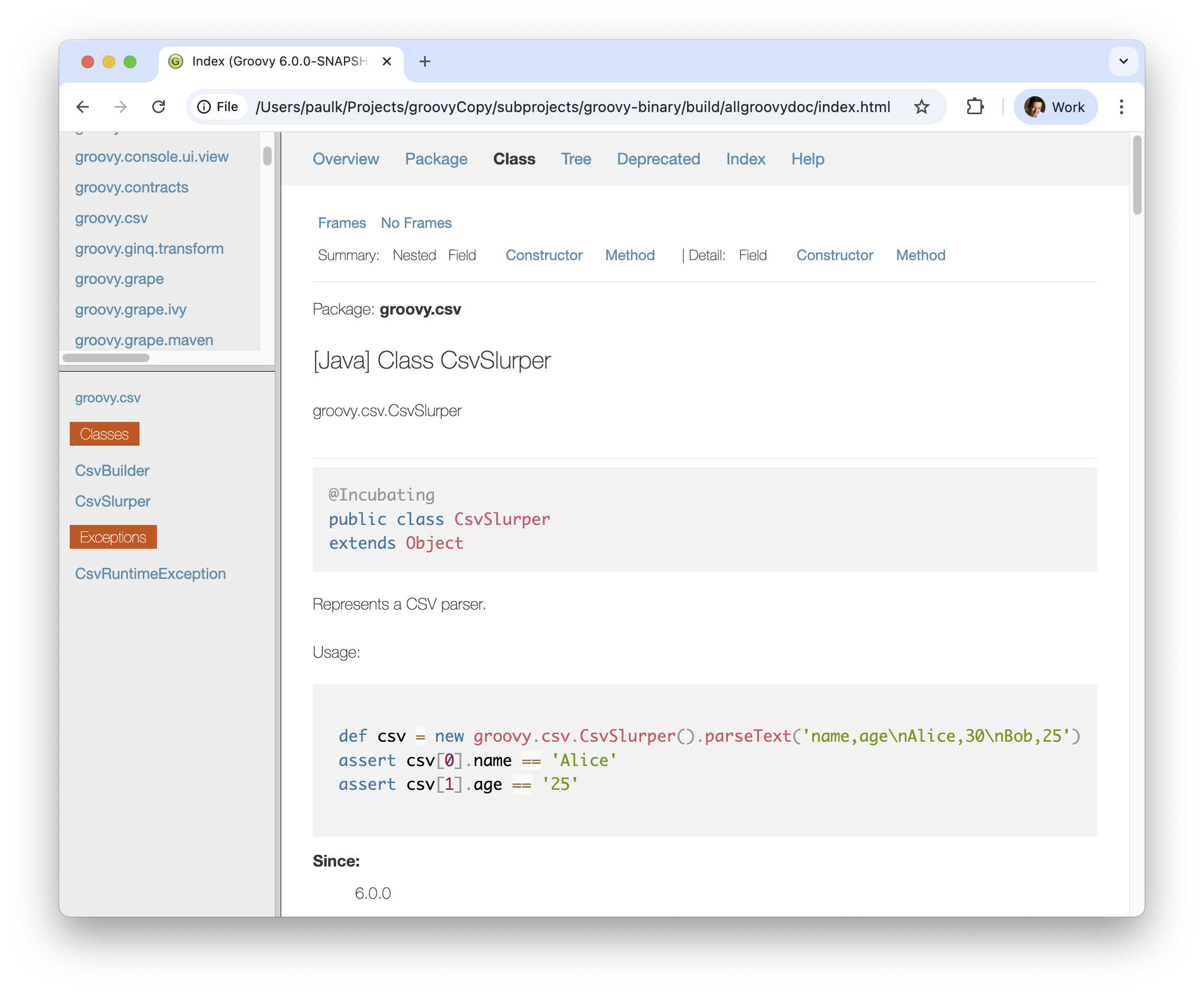
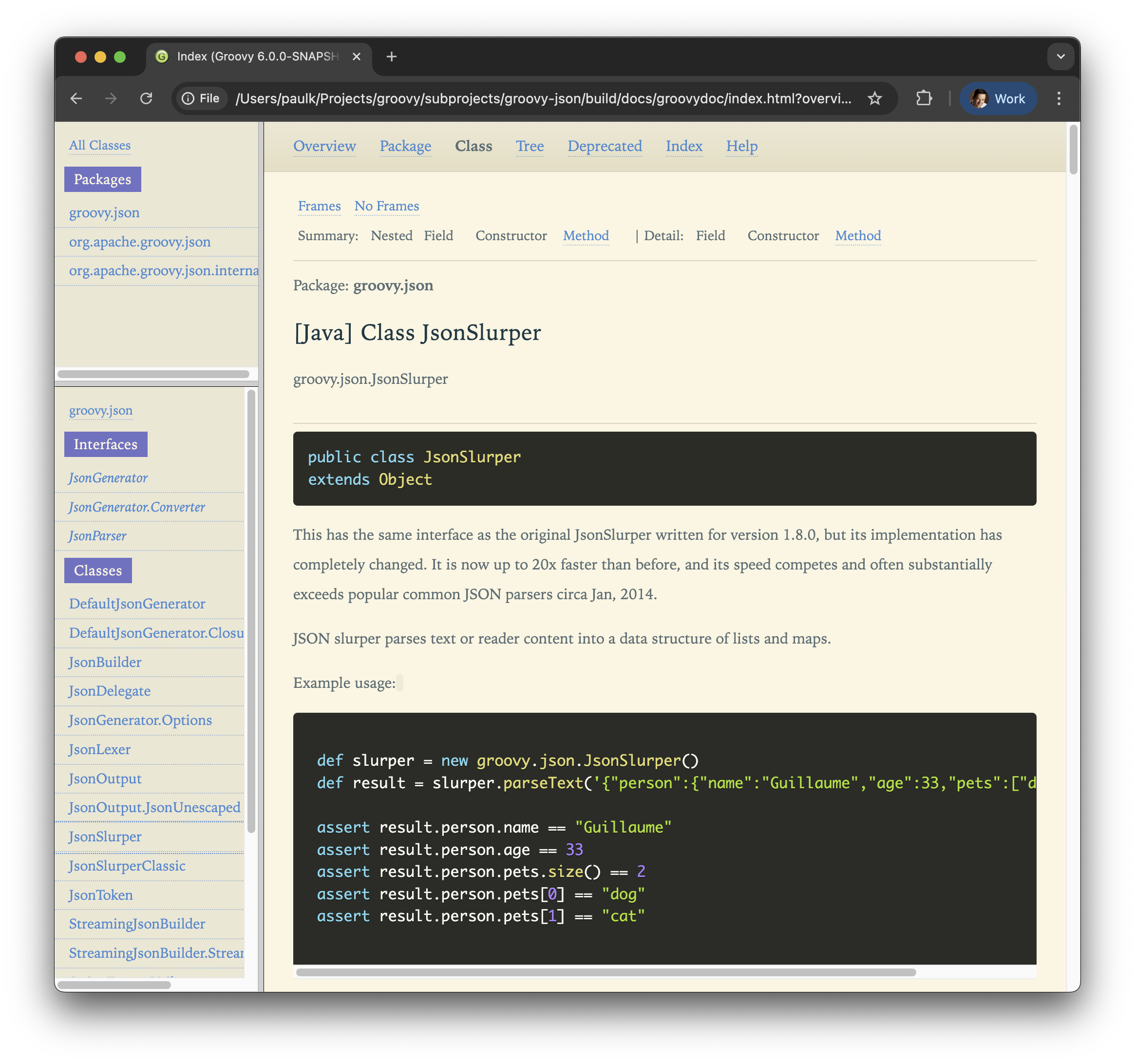
docgenerator (Groovy user guide)
The same theming model has been extended to docgenerator, the
tool that produces the Groovy user guide and other
distribution-bundled documentation. Output supports light, dark,
and custom themes, following the OS preference by default and
sharing the GroovyDoc CSS-custom-property approach so that custom
stylesheets remain palette-aware.
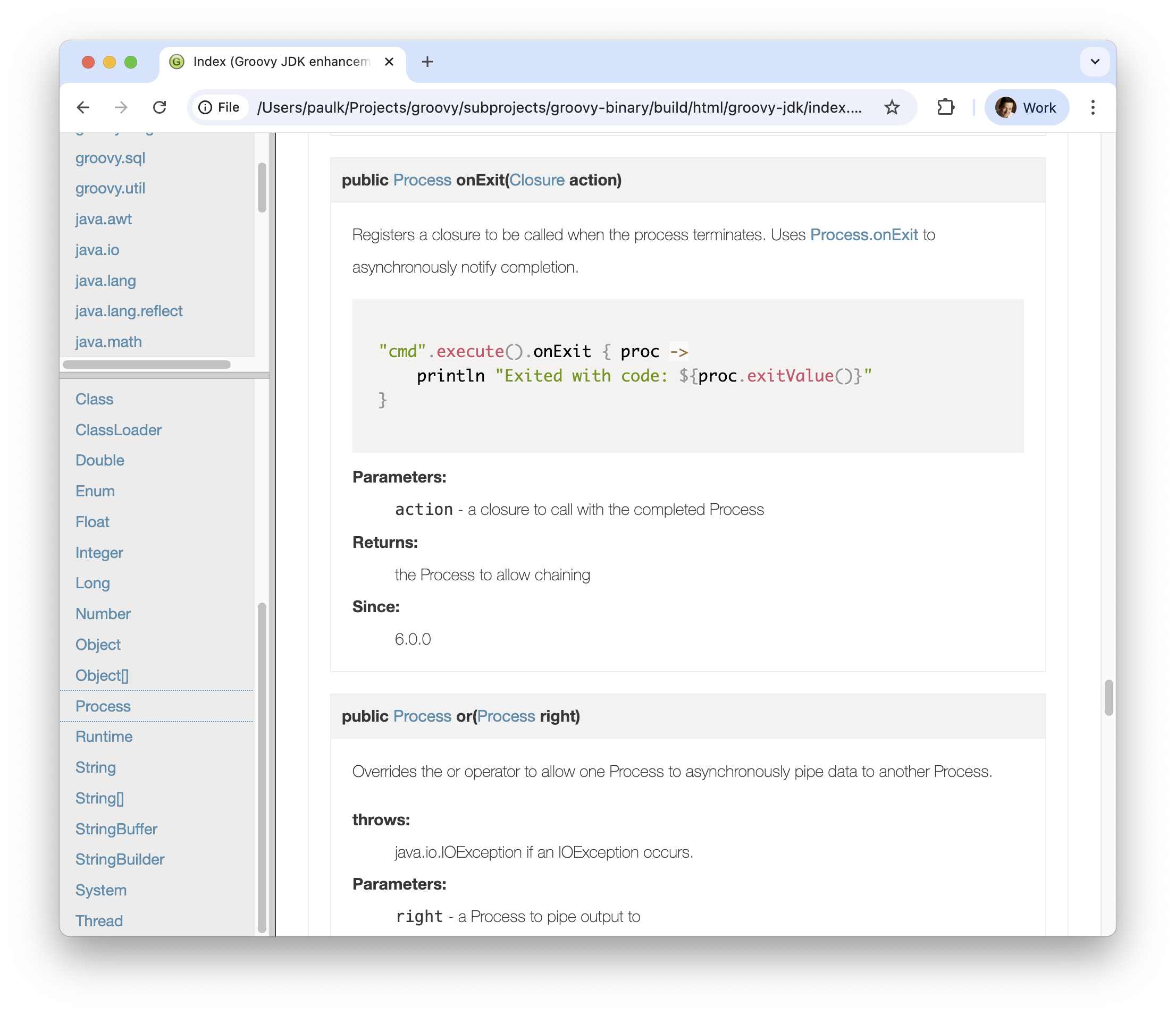
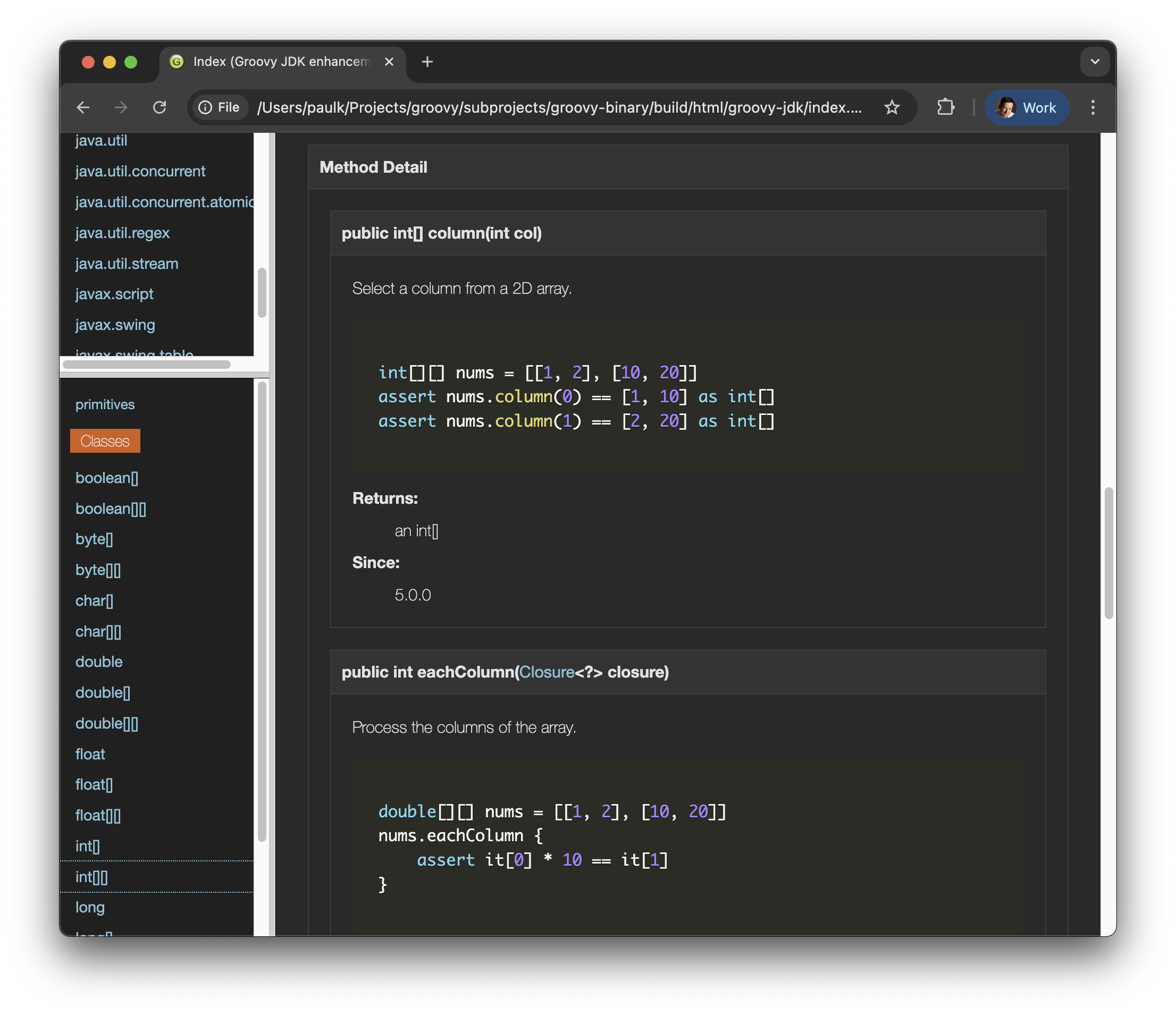
GroovyConsole
GroovyConsole now offers light, dark, follow-system, and custom theme options, applied across the editor pane, output pane, and surrounding chrome. The active choice is persisted between sessions.
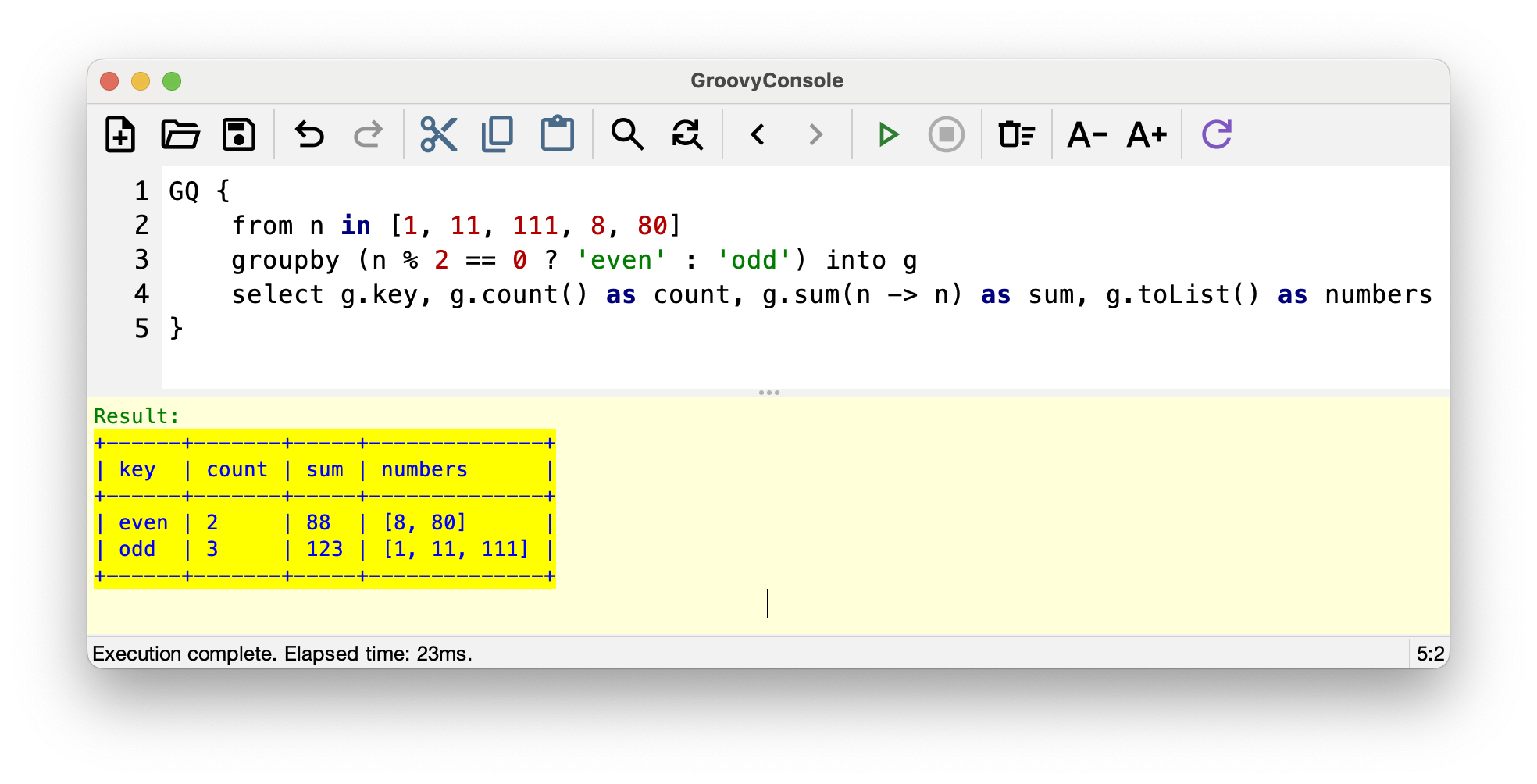
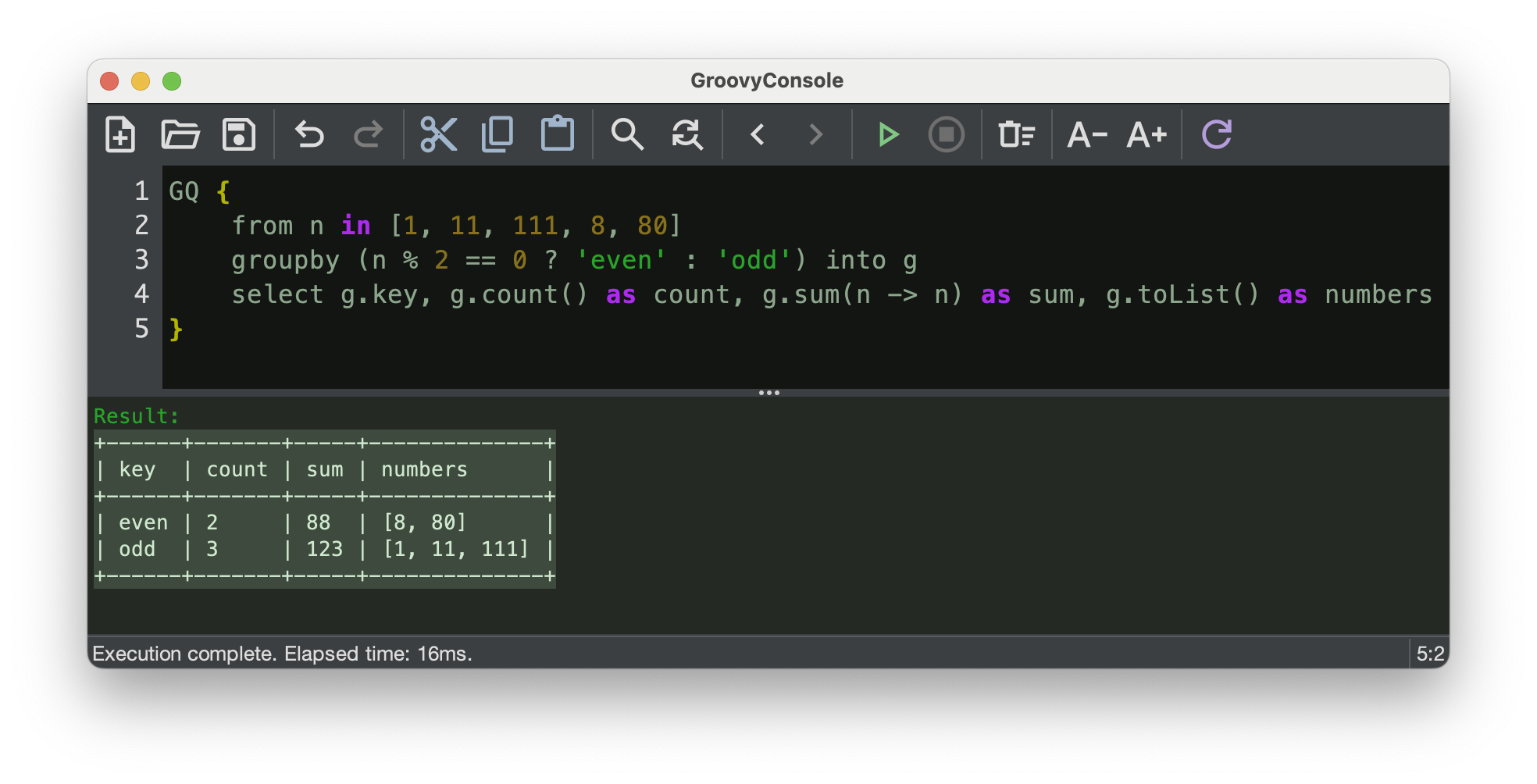
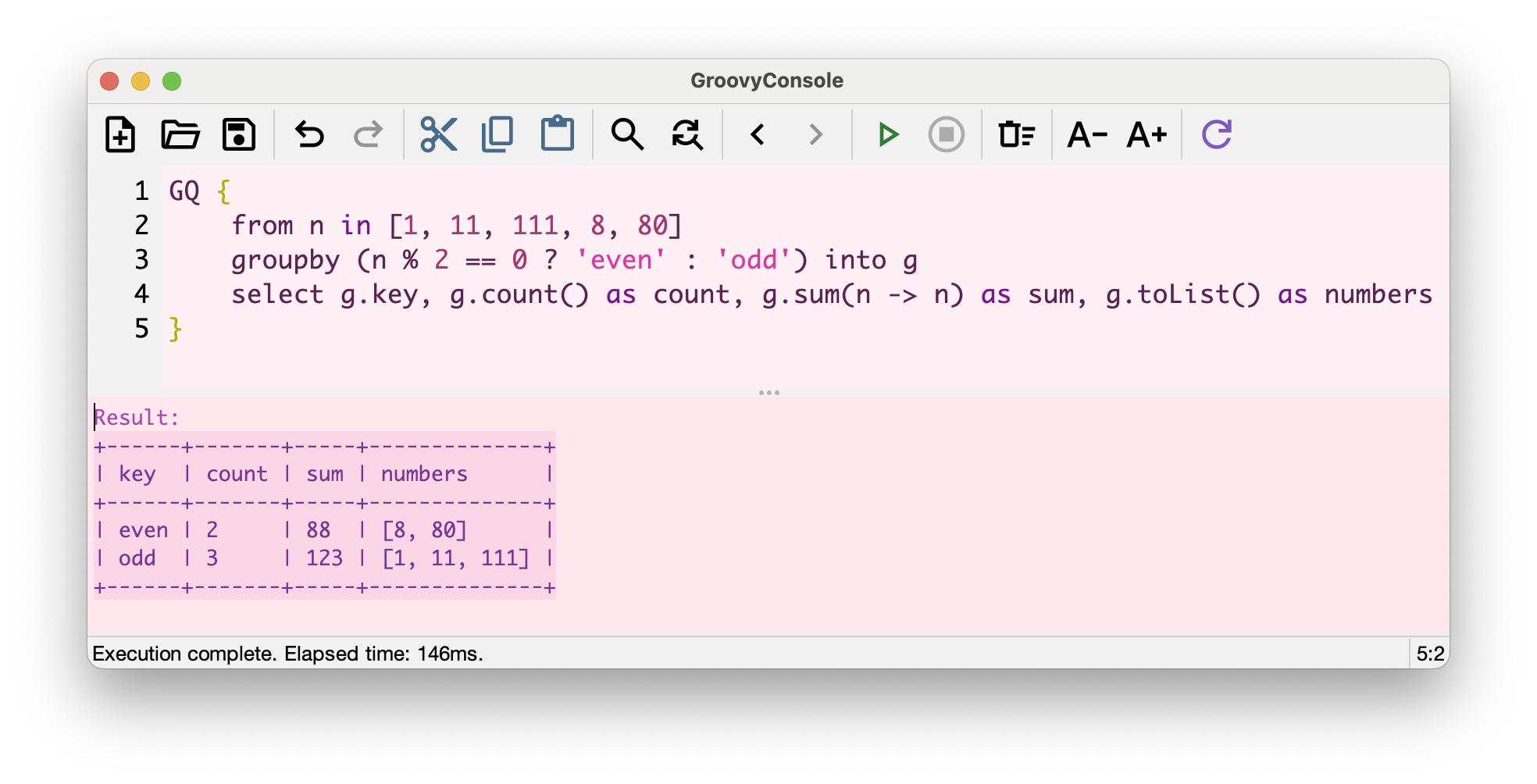
GroovyDoc Enhancements
Groovy 6 brings GroovyDoc substantially closer to modern Javadoc
feature parity and adds a few enhancements of its own. The two
headline items are support for JEP 467 Markdown doc comments and
JEP 413 {@snippet} code snippets, both working in .groovy and
.java sources.
Markdown doc comments (JEP 467)
A run of /// line comments can now be used as a doc comment whose
body is CommonMark Markdown
(GROOVY-11542):
/// # Greet
///
/// Returns a friendly greeting. Inline tags still work:
/// {@link String} and {@code greet}.
///
/// ```groovy
/// assert greeter.greet('world') == 'Hello, world'
/// ```
///
/// @param name the subject to greet
/// @return the greeting
String greet(String name) { "Hello, $name" }Headings, bullets, fenced code blocks, emphasis, and inline code all
render as you would expect. Headings are shifted down two levels
(so # becomes <h3>), fitting under each page’s existing title
structure. Inline Javadoc tags continue to work inside Markdown
bodies; tag-like text inside fenced code blocks stays literal.
Traditional /** … */ Javadoc blocks still work and can coexist
with /// comments in the same source file.
See JEP 467 and CommonMark for the full syntax and semantics.
Code snippets via {@snippet}
The JEP 413 {@snippet} tag is now supported
(GROOVY-11938)
in three forms. Inline body:
/**
* {@snippet lang="groovy" :
* def greet(name) { "Hello, $name" }
* greet('world')
* }
*/External reference to a file in the package’s snippet-files/
directory (a region can also be selected via region="name"):
/** {@snippet file="GreetExample.groovy"} */Markup comments inside snippet bodies let authors highlight, replace, or link to portions of the code without editing the source itself:
/**
* {@snippet lang="groovy" :
* def greet(name) { "Hello, $name" } // @highlight substring="greet"
* // @link substring="Greeter" target="Greeter"
* Greeter.instance.greet('world')
* }
*/@highlight, @replace, and @link all support substring=,
regex=, and region= attributes. See
JEP 413 for the full markup
reference.
Two author-facing conveniences apply to the external form: the
language class is inferred from the file’s extension when no
explicit lang="…" is given, and a leading license or copyright
header in the referenced file is stripped from the rendered output
(opt out with keepHeader=true). See the
dochome:groovydoc.html[Groovydoc
documentation] for the full list of recognised extensions and the
header-detection heuristic.
Syntax highlighting and dark mode
Two new generator flags make the rendered output immediately more modern:
groovydoc -syntaxHighlighter prism -theme auto ...-syntaxHighlighter=prism bundles
Prism.js for client-side syntax highlighting
of {@snippet} blocks and Markdown fenced code. Groovy, Java, XML,
JSON, YAML, TOML, SQL, CSV, Markdown, JavaScript, and regex are
supported out of the box.
-theme controls the palette strategy
(GROOVY-11947):
-
auto(default) — follow the reader’s OSprefers-color-scheme. Light and dark palettes are both emitted; the browser picks at view time. Syntax highlighting swaps themes in sync (GROOVY-11946). -
light/dark— lock the output to one palette regardless of OS preference.
Under the hood, the default stylesheet has been refactored around
semantic CSS custom properties (--fg, --bg, --link,
--bg-panel, etc.). Author stylesheets supplied via
--add-stylesheet can reference the same tokens and become theme-aware
automatically.
Highlighting legacy <pre> blocks
The new -preLanguage <lang> option (CLI) / preLanguage="lang"
attribute (Ant task) sets a default Prism language for unattributed
<pre> blocks in doc comments, so legacy code samples get
highlighted without source edits
(GROOVY-11950).
See the
dochome:groovydoc.html[Groovydoc
documentation] for the rewrite rules and the per-block opt-out.
Feature summary
Smaller improvements that collectively close the long-standing gap with modern Javadoc:
| Feature | Description |
|---|---|
Class hierarchy tree pages |
|
Script documentation |
Top-level scripts now get documented; leading |
|
Members annotated with |
|
Inlines compile-time constants. Supports |
|
Pulls in the parent class’s/interface’s corresponding documentation — including from external (JDK) classes, resolved from the local JDK source archive (GROOVY-3782, GROOVY-11988) |
|
Recognised with proper heading labels (e.g. "Implementation Requirements:" rather than raw tag names) (GROOVY-11945) |
|
Annotation references are only emitted when the annotation type
itself is |
|
Per-package directories are copied verbatim to the output for sibling images, diagrams, and external snippet sources (GROOVY-5986) |
|
Add a custom stylesheet alongside the default (contrast with
|
Optional-page toggles |
|
Ant |
JPMS-style module segment in external-link URLs for JDK 9+ Javadoc layouts (GROOVY-11682) |
Non-zero exit on errors |
CLI returns a non-zero exit code when source files fail to parse, so CI jobs fail rather than silently succeed (GROOVY-9057) |
Miscellaneous fixes |
No spurious |
Build tool support
The new options above are exposed through the GroovyDoc CLI
(groovydoc) and the Ant task. Gradle’s built-in groovydoc
task currently lags behind both surfaces and does not yet expose
every new flag.
Until that gap closes, we recommend either driving GroovyDoc via the Ant task from Gradle, or replicating the approach used by the Apache Groovy and Grails builds themselves — both projects wrap GroovyDoc in their own plugin/build glue to access the full feature set.
Improved Annotation Validation
Groovy 6 closes gaps in annotation target validation for Groovy-specific annotation targets (GROOVY-11884), and to now be fully compliant with JLS 9.6.4.1 (GROOVY-11838) for normal Java targets.
Previously, annotations could be placed on import statements and loop statements without validation — for example:
@Deprecated import java.lang.Stringwould compile without error even though @Deprecated does not target imports.
The compiler now enforces that only annotations explicitly declaring Groovy-specific targets are permitted in these positions. A new @ExtendedTarget meta-annotation with an ExtendedElementType enum defines two Groovy-only targets:
-
IMPORT— for annotations valid on import statements (e.g. @Grab and related annotations, @Newify, @BaseScript) -
LOOP— for annotations valid on loop statements (e.g. @Invariant, @Decreases, @Parallel)
Annotations without the appropriate @ExtendedTarget declaration
are now flagged as compile errors when applied to these constructs.
This is a breaking change for code that
previously relied on the lenient behavior.
Java Compatibility
Groovy 6 narrows the gap with Java syntax in a few places, so that code copied from Java sources compiles without the previously required Groovy-specific rewrites.
Module import declarations
Groovy 6 supports Java’s module import declarations (GROOVY-11896), giving scripts and classes a concise way to pull in every public type exported by a named module with a single statement:
import module java.sql
def conn = DriverManager.getConnection('jdbc:h2:mem:test')
def stmt = conn.createStatement()An import module java.sql is equivalent to a star import
(import pkg.*) for every package the module exports, and also
covers packages reached via requires transitive. For example,
a single import module java.sql makes Connection and
DriverManager directly available, along with types like
javax.xml.transform.Source (from java.xml) and
java.util.logging.Logger (from java.logging).
Module imports work with system modules (JDK modules like
java.base, java.sql, java.desktop), JPMS modules from modular
JARs on the classpath, and automatic modules. Explicit single-type
imports take priority, so naming conflicts can be resolved by
adding a specific import:
import module java.desktop
import java.util.List
// The explicit single-type import wins over
// the module-expanded java.awt.List
assert List.name == 'java.util.List'The module keyword is context-sensitive — it remains usable as
a variable, method, or class name. Wildcard
(import module java.base.*) and alias
(import module java.base as jb) forms are not supported.
See JEP 511 for the corresponding
Java language feature.
Array initializers in annotations
-
Array initializer syntax (
{…}) is now accepted in annotation attribute values, matching Java — e.g.@A(name={})and@A(name={""})on a class. Previously these required explicitnew String[]{…}syntax (GROOVY-11866). -
Array initializer syntax is also accepted in annotation default values within
@interfacedeclarations — e.g.String[] value() default {}(GROOVY-11845).
Labeled break targeting non-loop blocks
Labeled break targeting a labeled (non-loop) block now correctly
exits that block, matching Java. Previously the break exited only
the innermost enclosing loop, causing statements after the labeled
block to re-execute
(GROOVY-6844,
GROOVY-7463).
Intersection-type casts for lambdas, method references and closures
Groovy 6 accepts Java’s intersection-type cast syntax on lambdas, method references and closures, so that a single expression can be declared to satisfy several interface contracts at once (GROOVY-11998):
Runnable r = (Runnable & Serializable) () -> println('hello')The cast carries through static compilation: when one of the bounds
is Serializable, the generated synthetic class implements
Serializable and emits the required $deserializeLambda$ plumbing,
so the resulting lambda can be persisted, sent across JVMs, or used
in frameworks that rely on serialised lambdas (such as JPA Criteria
APIs and some distributed-computing libraries). The same applies to
method references
(GROOVY-11993) — a (Supplier<String> & Serializable)-typed text::trim survives a
round-trip through ObjectOutputStream/ObjectInputStream.
The non-functional bounds are passed through to
LambdaMetafactory as marker interfaces, so reflective checks
(instanceof Serializable, instanceof Cloneable, …) on the
resulting object behave as Java programmers expect.
In addition to the Java-style cast, Groovy’s as coercion accepts the
same intersection form — handy when coercing a closure rather than a
lambda:
def r = { println 'hello' } as (Runnable & Serializable)Other Core API Changes
-
ASTTransformationCustomizernow supports annotations whose@GroovyASTTransformationClasslists multiple transforms (e.g.@Sealed,@RecordBase) and@AnnotationCollectoraliases (e.g.@AutoExternalize), via a newforAnnotation(…)static factory that returns one customizer per resolved transform class (GROOVY-11973). For example:config.addCompilationCustomizers(*ASTTransformationCustomizer.forAnnotation(Sealed)). -
The Groovy 5.0 change to
File/Pathtruthiness — whereby a non-existent file is falsy — can be reverted as a porting aid by setting-Dgroovy.truth.file.exists.enabled=false. With the flag set tofalse, any non-nullFileorPathreference is truthy (matching Groovy 4 behaviour); the default (true) preserves the Groovy 5 existence-aware semantics (GROOVY-11996). -
Tuple.equalsnow follows Groovy’sListequals semantics: aTuplecompares equal to anyListwith the same elements (element-wise, using Groovy equality), rather than requiring anotherTuple(GROOVY-12017). -
The
invokedynamicpolymorphic inline cache uses a single background daemon thread (namedPIC-Cleaner) to evict GC-cleared entries. Setting-Dgroovy.indy.callsite.cleaner.inline=trueprevents that thread from starting and performs the (otherwise identical) cleanup inline on the calling thread instead. The default (false) keeps the background thread. This is primarily useful for tests and tools such as deterministic concurrency checkers, which can mistake the perpetually parked daemon for a deadlocked thread (GROOVY-12092).
Other Module Changes
For the groovy-xml module changes (secure-by-default XML processing,
StAX streaming helpers, SerializeOptions, and named-parameter
construction), see XML Processing Improvements.
-
groovy-sql: The
DataSetclass now correctly handles non-literal expressions in queries (GROOVY-5373). -
groovy-sql: New
Sql.inListhelper expands a collection into the parameter list of a SQLINclause, avoiding manual string concatenation (GROOVY-5436). -
groovy-sql: Added Map-based named-parameter overloads for
call,callWithRows, andcallWithAllRows, matching the existing named-parameter support oneachRow,rows, etc. (GROOVY-11936). -
groovy-ant: The
<groovy>Ant task now inherits the surrounding project’s Ant properties when running in forked mode, matching the behaviour of non-forked execution (GROOVY-6908). -
groovy-ant: The
<groovyc>task gains nested<jvmarg>,<sysproperty>, and<syspropertyset>elements (mirroring Ant’s<java>task) that are passed to the spawned compiler JVM whenfork="true", plus aninheritAllattribute to pass all parent- project properties as system properties at once. Useful for compile-time configuration consumed by AST transforms, the parser/lexer, or annotation processors — for example<jvmarg value="--add-opens=java.base/java.lang=ALL-UNNAMED"/>or<sysproperty key="groovy.val.enabled" value="false"/>. Explicit<sysproperty>/<syspropertyset>entries take precedence on name collision withinheritAll(GROOVY-11995). -
groovy-jmx: Removed dead IIOP support and refreshed documentation (GROOVY-11921).
-
groovy-servlet: Jakarta EE 11 compatibility (GROOVY-11922).
-
groovy-json:
JsonSlurpernow enforces a maximum nesting depth (default 1000) when parsing, guarding against stack exhaustion from maliciously deep documents. The limit is configurable per parser viasetMaxNestingDepth(int)(a value⇐ 0disables the check) or globally with thegroovy.json.maxNestingDepthsystem property (GROOVY-12064).
Breaking changes
Removal of Security Manager support
Java’s Security Manager has been deprecated for removal by JEP 411, which argues that it is rarely used to secure modern applications and that security is better achieved through other mechanisms such as containers and operating system security.
Groovy 6 removes its use of AccessController.doPrivileged calls
and related Security Manager infrastructure
(GROOVY-10581).
Code that relied on Groovy’s Security Manager integration
should adopt alternative security mechanisms.
Groovy 5 still includes such support on JDK versions that support it.
Other changes
-
valis now a contextual keyword for declaring final variables (seevalKeyword for Final Declarations). A few pre-existing edge cases around the siblingvarkeyword now apply tovalas well — chiefly a field namedvaldeclared immediately before a method or constructor, andval as Typecast expressions. The-Dgroovy.val.enabled=falsesystem property reverts to the prior behavior as a porting aid. (GROOVY-9308, GROOVY-11994) -
Annotation target validation is now enforced for import and loop statements (see Improved Annotation Validation). (GROOVY-11884)
-
The inner class
methodMissingandpropertyMissingprotocol was redesigned. Some scenarios that previously allowed access to an outer class’s members through an inner class instance (e.g. accessing outer fields via an object expression, outer classinvokeMethod/MOP overloads from anonymous inner classes) may no longer work. (GROOVY-11853) -
When multiple
set(String, …)method overloads exist, Groovy now selects the best-matching overload based on the value type rather than always using the same method. This fixes incorrectGroovyCastExceptionerrors at runtime but may change which setter is invoked if your code relied on the previous behavior. (GROOVY-11829) -
TomlSlurperandYamlSlurperno longer prematurely closeReaderandInputStreamarguments passed to parsing methods. Callers are now responsible for closing resources they create, following standard conventions. (GROOVY-11925, GROOVY-11926) -
XmlParser.parse(File)andXmlParser.parse(Path)now properly close the underlyingInputStreamafter parsing (see XML Processing Improvements). Previously, the stream was not closed, which could cause file descriptor leaks. (GROOVY-11927) -
XmlParser.setNamespaceAware(boolean)now throwsIllegalStateExceptionif called after parsing has started (see XML Processing Improvements). Previously, the setter silently updated the field but had no effect since the SAX parser was already configured. (GROOVY-7633) -
groovy-xml hardening: three default-behaviour changes to behind-the-scenes XML factory creation paths — see XML Processing Improvements for the security rationale and per-API details. The front-line parsers (
XmlParser,XmlSlurper, the staticDOMBuilder.parse(…)overloads,XmlUtil.newSAXParser) were already secure-by-default and are unaffected. Migration knobs: (1)SerializeOptions.allowExternalResources = truere-enables external XSL imports/includes and external DTD references inXmlUtil.serialize. (2) Direct callers of the zero-argFactorySupport.createDocumentBuilderFactory()/createSaxParserFactory()parsing DOCTYPE-bearing input should switch to the new(true)overload. (3) Code that reaches intodomBuilder.documentBuilderand parses DOCTYPE-bearing XML directly should use the new three-argDOMBuilder.newInstance(validating, namespaceAware, allowDocTypeDeclaration). (GROOVY-11981) -
The last references to
javax.swing.JApplethave been removed fromgroovy-swing(theSwingBuilderfactory registration) and from the Groovy Console.JAppletwas deprecated for removal since Java 9 and has been removed in JDK 26, so these references would otherwise causeNoClassDefFoundErroratSwingBuilderinitialisation on JDK 26+. Code that explicitly used the applet-related factories should migrate to standardJFrame/JWindowalternatives. (GROOVY-11912) -
StringGroovyMethods#stripIndent(boolean)now handles non-Stringarguments as documented. Previously certain non-StringCharSequenceinputs were not stripped as advertised; affected code now produces the documented (stripped) result. (GROOVY-12009) -
IntRange.containsWithinBoundsno longer delegates tocontains, restoring the continuous-bounds contract (the bounds check ignores any non-unit step). Code that relied on the previous step-aware delegation may see different results. (GROOVY-12067) -
ClassNodeUtils.getPropNameForAccessornow uses JavaBeans decapitalization, matching runtime property naming (e.g. an accessorgetURLmaps to propertyURL, notuRL). This corrects property-name derivation in AST transforms and type checking but may change derived names in code that relied on the prior behaviour. (GROOVY-12058) -
SourceTextnow slices source using UTF-16 offsets aligned with the code-point columns carried by the AST, so retrieved source containing supplementary characters (e.g. emoji, some CJK) is no longer truncated. Tooling that compensated for the previous truncation may need adjustment. (GROOVY-12085)
Under exploration (before GA release)
-
Further performance improvements
-
Further improvements to the language specification documentation
JDK requirements
Groovy 6 requires JDK17+ to build and JDK17 is the minimum version of the JRE that we support. Groovy 6 has been tested on JDK versions 17 through 26.
CompilerConfiguration also recognises a JDK27 ("27")
targetBytecode value, mapped to the corresponding ASM V27 class-file
version, ahead of that JDK’s general release
(GROOVY-12028).
Known issues
The following issues were noticed after alpha-1 was released:
-
Missing
groovy.val.enabledflag (GROOVY-11994) -
groovydocCLI fails with "Unsupported Java Version: false" when--javaVersionomitted (GROOVY-11987)
These will be fixed in the next pre-release and are already fixed in the most recent snapshots.
More information
You can browse all the tickets closed for Groovy 6.0 in JIRA.